昨日書いた泉鏡花『貧民倶樂部』の記事において,鏡花テクスト引用のために大量のルビをマークアップしなければならなかった。HTML で <ruby>
このツールは,標準入力から UTF-8 テキストを読み,此(これ)のように,漢字 + ( + 読み + )のように書いた文字列に対して,マークアップを行う。デフォルトでは HTML タグを付加する。-l オプションを指定すると LaTeX 形式で整形する。対象テキストの括弧は全角でないといけない。そういう融通の利かないところがある。開括弧より前のテキストを後ろから逆方向に走査し,漢字以外が出現するまで漢字をスタックにプッシュし,あとでこのスタックからポップして得られる文字列(先入れ後出しにより文字の順番が戻る)を親文字と判定する。「漢字」は Unicode CJK 統合漢字に属するかを \p{InCJKUnifiedIdeographs} 正規表現文字クラスで判断している。Perl コードは以下の通り。
#!/usr/bin/perl -w
# -*- coding: utf-8; mode: cperl; -*-
#
# convertruby: ルビ・マークアップ
# - ベタのテキストを <ruby> or \ruby シーケンスに整形する
# - 例: 此(これ) ["(", ")" は全角括弧]
# -> <ruby><rb>此</rb><rp>(</rp><rt>これ</rt><rp>)</rp></ruby> (default)
# -> \ruby{此}{これ} (with -l option)
# - usage: convertruby [-l] < stdin
# -l: for LaTeX; default: for HTML
#
use strict;
use utf8;
use Getopt::Std;
use File::Basename;
binmode(STDOUT, ":utf8");
# コマンドライン・オプション処理
my %opts = ('l' => 0);
Getopt::Std::getopts('l', \%opts) ||
die "Usage: " . basename($0) .
" [-l] \< (stdin)\n -l: for LaTeX; default: for HTML\n";
# 行毎の主処理
while (<STDIN>) {
my $line = $_;
utf8::decode($line); utf8::decode($_);
my ($yomi, $leftt, $rightt);
# 「(読み)」を含まない行はそのまま出力
unless ($_ =~ /([^)]*)/gi) {
print $line; next;
}
# 「(読み)」を走査し,これがある限りその前後を切り出す
while ($line =~ /([^)]*)/gi) {
$yomi = $&; $leftt = $`; $rightt = $';
# 「(読み)」から括弧を外す
$yomi =~ s|[()]||g;
# 対象漢字部を後方から走査し,漢字スタックに push する
my @kstack = (); my $k;
my @istack = split(//, $leftt); # 「読み」の左側テキストの文字配列
while ((@istack) &&
(($k = pop(@istack)) =~ /\p{InCJKUnifiedIdeographs}/g)) {
push(@kstack, $k); $k = "";
}
# 最後に pop した非漢字を左側テキスト配列スタックに戻しておく
push(@istack, $k) if ($k);
# 漢字スタックから漢字部文字列を pop で復元
my $kanji = "";
while (@kstack) {
$kanji .= pop(@kstack);
}
# 抽出した漢字部よりも前の文字列を出力
if (@istack) {
print $_ for @istack;
}
# ruby マークアップ部分を出力
if ($kanji) {
if ($opts{'l'}) {
# LaTeX (with -l option)
print '\ruby{' . $kanji . '}{' . $yomi . '}';
} else {
# HTML (default)
print '<ruby><rb>' . $kanji .
'</rb><rp>(</rp><rt>' . $yomi . '</rt><rp>)</rp></ruby>';
}
} else {
# 「漢字(読み)」のパターンでないものはそのまま出力
print "($yomi)";
}
# 走査対象文字列に右側テキスト(残り)文字列を格納して,繰り返し
$line = $rightt;
}
# 残り文字列を出力
print $rightt if ($rightt);
}
GNU Emacs からは,以下を .emacs に追加すれば,利用できるようになる。ここでは convertruby は /usr/
;; convertruby for HTML (defun convert-ruby-html (start end) "Convert text to ruby HTML sequence." (interactive "r") (call-process-region start end "/usr/local/bin/convertruby" t (list t nil) nil "") ) ;; convertruby for LaTeX (defun convert-ruby-latex (start end) "Convert text to ruby HTML sequence." (interactive "r") (call-process-region start end "/usr/local/bin/convertruby" t (list t nil) nil "-l") )
泉鏡花『貧民倶樂部』の引用に際しては,新字・新仮名遣いで引用文を作成し(図 1),自作のソフトで旧字・旧仮名遣いに変換し,次に,ルビを付けたい漢字に「(よみ)」を付加し(図 2),最後に Emacs 上で convertruby を実行して <ruby> タグをマークアップした(図 3)。ただし,図 3-1 は HTML 整形の,図 3-2 は LaTeX 整形の結果例である。
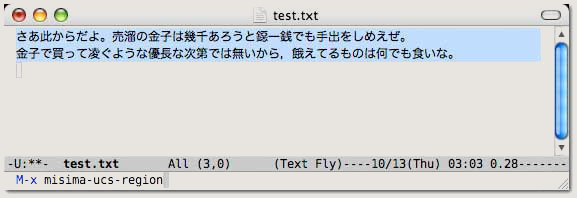 図 1. ルビなしで新字・新仮名遣いで記述
図 1. ルビなしで新字・新仮名遣いで記述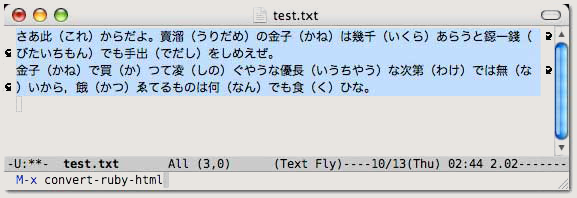 図 2. 表記変換後,ルビを付加
図 2. 表記変換後,ルビを付加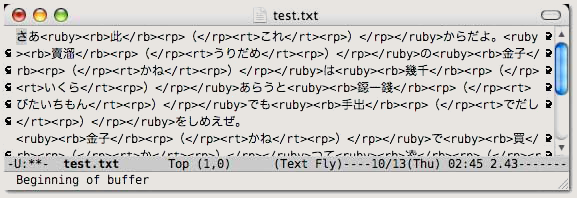 図 3-1. HTML 整形実行結果
図 3-1. HTML 整形実行結果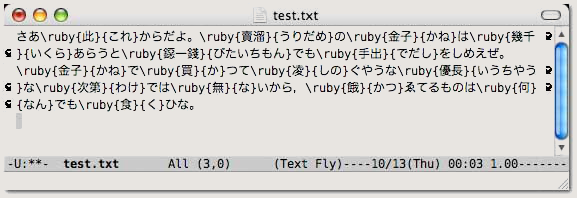 図 3-2. LaTeX 整形実行結果
図 3-2. LaTeX 整形実行結果