以前,『Excel ワークシートの一括 CSV 変換』記事で,Spreadsheet::
しかしその後,このプログラムだと,JISX 0213 の文字のうち Unicode コードポイント U+20000 以上の拡張領域にある漢字がすべて x'EFBFBD' に文字化けしてしまうことがわかった。Spreadsheet::
入力の Excel ファイル (jisx0213-extarea-tbl.
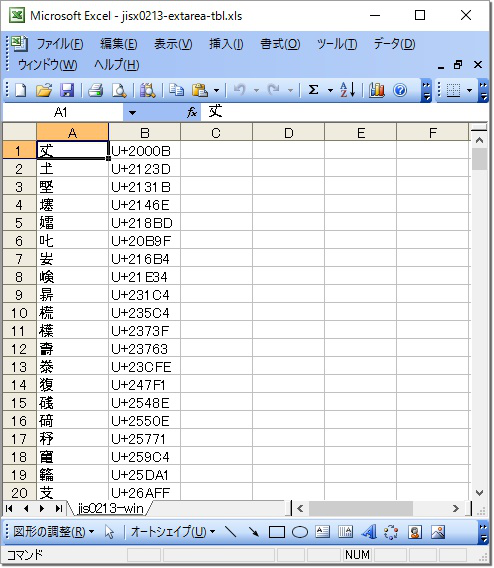
図 1. 入力 Excel: jisx0213-extarea-tbl.xls
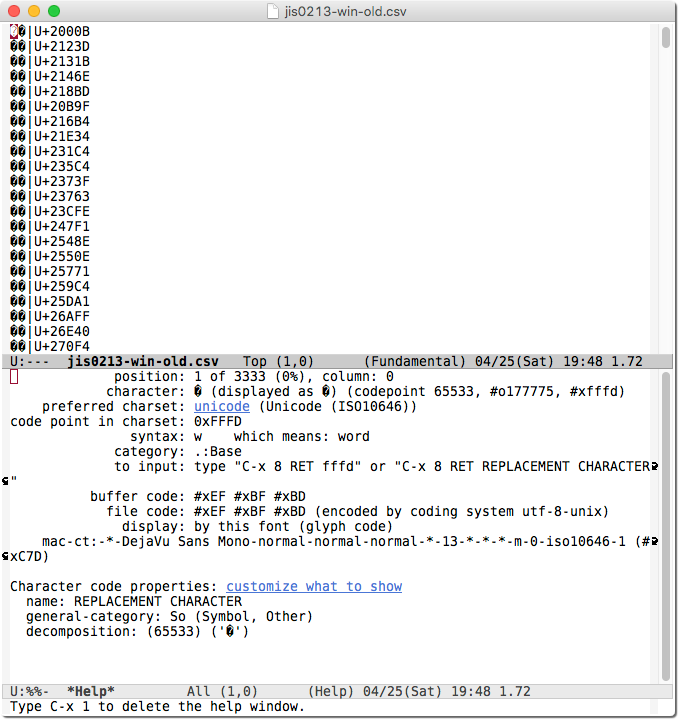
図 2. 出力 CSV (漢字が文字化け)
そこで,文字化け対策として,今回は Python3 言語を用いて,Excel - CSV 変換プログラムを書いた。果たして,U+20000 以上の拡張領域の文字もきちんと抽出できた。
以下,Excel から CSV を抽出するプログラム,CSV から Excel 2007 ブックを生成するプログラム,及び Excel ブックの属性変更を行うプログラムの例について示す。Excel データを読み書きする openpyxl 及び,データサイエンスライブラリ Pandas のモジュールが必要なので,あらかじめ “pip install pandas openpyxl” にて組み込んでおく。
なお,本稿で作成するプログラムの前提として,CSV のセパレータは “|”(vertical line, x'7c') としている。また,データ中にセパレータ文字を使う場合のエスケープ文字は,“\”(backslash, x'5c') としている。
xlsxtocsv.py: Excel から CSV を抽出する
Excel ブックに含まれるすべてのシートについて,データを CSV 形式で出力する手順は概ね次のとおりである。
- pandas の ExcelFile("Excel ファイル名") 関数により,Excel ブックオブジェクト (ここでは xls_book とする) を読み込む。
- xls_book.
sheet_names で参照できる Excel シート名毎に以下処理を行う。 - xls_book.
parse (sheet_name=シート名, opts) 関数により,シートのデータを読み込んで,pandas DataFrame オブジェクト (ここでは df) に格納する。 - DataFrame オブジェクト df の to_csv
(CSV ファイル名, opts) メソッドにより,指定したファイルに CSV データを書き出す。
実装 xlsxtocsv.py のコードを以下に示す。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
#
# xlsxtocsv.py: Excel to CSV
#
# 2020(c) isao yasuda, All Rights Reserved.
# $Id: xlsxtocsv.py 488 2020-04-11 16:02:10Z isao $
#
# DESCRIPTION
# -----------
# - usage: xlsxtocsv.py xlsx-file
# - Excel Book を読んで,Sheet名.csv を書き出す
# - セパレータは '|'
# - " クォートしないようにする。(panda.DataFrame.to_csv quotechar='\\' 指定)
import os
import sys
import pandas as pd
# プログラム名
pn = os.path.basename(sys.argv[0])
# 引数チェック
if len(sys.argv) != 2:
print("usage:", pn, "excel-file")
exit(1)
print("*", pn + ":", "Excel file:", sys.argv[1])
# Excel Book 読み込み
xls_book = pd.ExcelFile(sys.argv[1])
# シートごとに内容を"シート名.csv"ファイルに書き出す
# - シートが存在するだけループ
for sht_name in xls_book.sheet_names:
# シートオブジェクトを DataFrame にセット
df = xls_book.parse(sheet_name=sht_name, header=None)
csv_fname = sht_name + '.csv'
print("*", pn + ": Sheet:", sht_name, "output to", csv_fname)
# DataFrame を「シート名.csv」で CSV 出力
df.to_csv(csv_fname,
index=False,
header=False,
sep='|',
quotechar='\\')
本プログラムの実行の様子を以下に示す。CSV 出力結果は図 3 のとおりである。文字化けせず正しく出力されている。
$ /xlsxtocsv.py jisx0213-extarea-tbl.xls * xlsxtocsv.py: Excel file: jisx0213-extarea-tbl.xls * xlsxtocsv.py: Sheet: jis0213-win output to jis0213-win.csv $
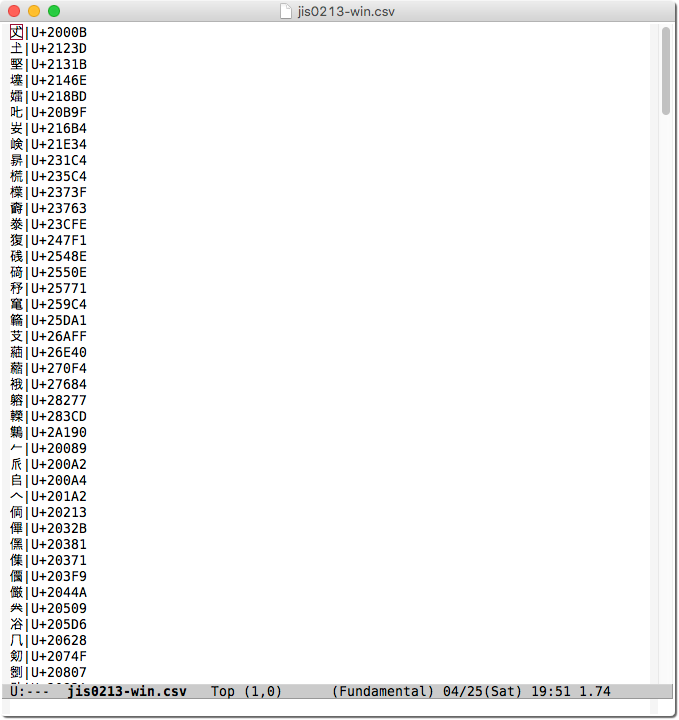
図 3. CSV 出力結果
csvtoxlsx.py: 複数の CSV ファイルから Excel ブックを生成する
複数の CSV ファイルを Excel シートとして格納し,Excel ブックを生成するプログラムを書く。その主な手順は以下のとおりである。
- 指定した CSV ファイル毎に以下を行う。
- csv モジュールの reader 関数で CSV データをオブジェクト (ここでは reader) に読み込む。
- reader オブジェクトから行のリストを組み立て,このリストから pandas DataFrame (ここでは sdf) を生成する。
- pandas の ExcelWriter
(Excel ファイル名, engine="openpyxl"[, opt]) 関数によりライタ (ここでは writer) を定義する。このとき,最初のシートの場合,opt に何も指定せず,2 シート目以降の場合,opt に mode="a" (追加モード) を指定する。 - DataFrame オブジェクト sdf の to_excel
(writer, sheet_ name=シート名, opts) メソッドにより,writer 指定で CSV ファイルに対応した Excel シートを生成する。
実装 csvtoxlsx.py のコードを以下に示す。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
#
# csvtoxlsx.py: CSV files to Excel Book
#
# 2020(c) isao yasuda, All Rights Reserved.
# $Id: csvtoxlsx.py 488 2020-04-11 16:02:10Z isao $
#
# DESCRIPTION
# -----------
# - usage: csvtoxlsx.py xlsx-file 0 1 2..
# - 0.csv, 1.csv,.. を読んで 0, 1,.. シート名からなる xlsx-file を生成する。
# - CSV のセパレータ '|'; 引用文字 \; エスケープ文字 \\;
import os
import sys
import csv
import pandas as pd
# CSV ファイルを読んで DataFrame を生成する関数
def genCSVDataFrame(csv_fname):
with open(csv_fname, newline='') as csvf:
reader = csv.reader(csvf,
delimiter='|',
quotechar='\'',
escapechar='\\')
csvlist = [row for row in reader]
return pd.DataFrame(csvlist)
# 主処理
# プログラム名
pn = os.path.basename(sys.argv[0])
# 引数チェック
argc = len(sys.argv)
if argc < 3:
print("usage:", pn, "xlsx-file 0 1 2 ..")
print(" 0, 1,..4: basename of 0.csv, 1.csv,.. 4.csv")
exit(1)
# Excel ファイルがすでに存在していたら削除
xlsx_fname = sys.argv[1]
if os.path.exists(xlsx_fname):
os.remove(xlsx_fname)
print("*", pn + ": old Excel Book:", xlsx_fname, "removed.")
# 引数の CSV ファイルごとに Excel シートを追加
# - 指定 CSV ファイル (sys.argv[2] 〜 (argc - 1)) 毎にループ
# - openpyxl エンジンで Excel シートとして出力
for i in range(2, argc):
sht_name = sys.argv[i]
csvfile = sht_name + '.csv'
print("*", pn + ": CSV file:", csvfile)
# CSV DataFrame を Excel に出力
sdf = genCSVDataFrame(csvfile)
if os.path.exists(xlsx_fname):
# すでに xlsx ファイルがあれば,当該シートを追加(二つ目以降の CSV ファイル)
with pd.ExcelWriter(xlsx_fname,
engine="openpyxl",
mode="a") as writer:
sdf.to_excel(writer,
sheet_name=sht_name,
index=False,
header=False)
print("*", pn + ": added Sheet:", sht_name, "to", xlsx_fname)
else:
# 存在しなければ,当該シートで xlsx ファイルを作成(最初の CSV ファイル)
with pd.ExcelWriter(xlsx_fname,
engine="openpyxl") as writer:
sdf.to_excel(writer,
sheet_name=sht_name,
index=False,
header=False)
print("*", pn + ": added Sheet:", sht_name, "to new", xlsx_fname)
本プログラムの実行の様子を以下に示す。生成された Excel ブックは図 4 のとおりである。
$ ./csvtoxlsx.py jisx0213-extarea-tbl.xlsx jis0213-win * csvtoxlsx.py: old Excel Book: jisx0213-extarea-tbl.xlsx removed. * csvtoxlsx.py: CSV file: jis0213-win.csv * csvtoxlsx.py: added Sheet: jis0213-win to new jisx0213-extarea-tbl.xlsx $
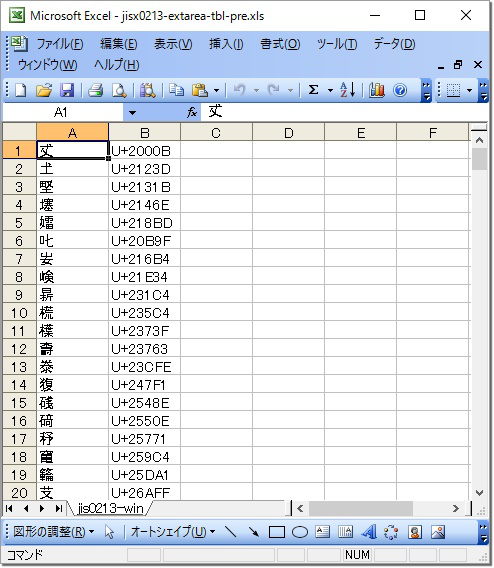
図 4. 出力 Excel ブック: jisx0213-extarea-tbl.xlsx
adjustxlsx.py: Excel ブックの属性を変更する
上記 csvtoxlsx.py で生成した Excel ブックのセル属性は,必ずしも利用者の意図に沿ったものとは限らず,フォントや,セルの格納文字列の長さに応じた幅・折り返し,左寄せ等の配置,といった属性を指定したい場合がある。
Excel ブックを読み,セル属性を設定変更して,当該ブックを上書きするプログラムを書く。その主な手順は以下のとおりである。
- openpyxl モジュールの load_
workbook (Excel ファイル名) 関数を用いて,Excel ブックオブジェクト (ここでは wb) を取得する。 - wb.sheetnames で得られるシート名リストの各シート名毎に以下を行う。
- 当該シート名をアクティブに設定する。ここではアクティブシートオブジェクトを ws とする。
- 設定したい属性に応じて,ws の行・列・セル単位で Font や Alignment によって属性をセットしていく。フォント属性や列幅は列単位で,行の高さは行単位でセットできる。水平・垂直の寄せ,折り返し表示等の配置属性については,セル単位に設定する必要があるようである。
- 属性設定を完了したら,ws.save(Excel ファイル名) でファイルをセーブし,ws.close() でクローズ処理を行う。
実装 adjustxlsx.py のコードを以下に示す。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# adjustxlsx.py - Excel 行・列幅,セル属性の調整
# 2020(c) isao yasuda, All Rights Reserved.
# $Id: adjustxlsx.py 488 2020-04-11 16:02:10Z isao $
# DESCRIPTION
# -----------
# - usage: adjustxlsx.py xlsx-file
# - Excel Book を読んで,シートごとに以下を行う
# (1)列幅を設定する。
# (2)行高を設定する。
# (3)フォント,テキスト配置のセル属性を設定する。
# - 同一ファイルに格納する。
import openpyxl as px
from openpyxl import Workbook
from openpyxl.styles import Alignment, Font
import os
import sys
# プログラム名
pn = os.path.basename(sys.argv[0])
# 引数チェック
if len(sys.argv) != 2:
print("usage:", pn, "xlsx-file")
exit(1)
# Excel Book オブジェクト
wb = px.load_workbook(sys.argv[1])
# シート名のリストを取得
sht_nm = wb.sheetnames
# セル属性
# - フォント: メイリオ, 11pt, ボールド無, 立体, アンダーライン無
font1 = Font(name='メイリオ', size=11, bold=False, italic=False,
vertAlign=None, underline='none', strike=False)
# - 配置: 左寄せ, 上寄せ, 折り返し表示, インデント無
aligment1 = Alignment(horizontal='center', vertical='center',
wrapText=True, indent=0)
# シート毎の設定
# - シートの数だけループし,セル属性を設定
# - インデックス i = 0: 文字; 1: コードポイント
sht_len = len(sht_nm)
for i in range(0, sht_len):
# アクティブシートの選択
ws = wb[sht_nm[i]]
print("*", pn + ": sheet:", sht_nm[i], "attribute setting")
# 列毎にフォント属性を設定
for coln in ["A", "B"]:
ws.column_dimensions[coln].font = font1
# 列毎に列幅を設定
# A列 B列
# 漢字|コードポイント
# 6 12
ws.column_dimensions["A"].width = 6
ws.column_dimensions["B"].width = 12
# 行毎に行高を設定
# - 18pt
# 当該行の列毎に配置属性を設定
# - 定義した alignment1 属性
# ws.max_row: シートの有効行数
print("*", pn + ":", sht_nm[i],
"items:", ws.max_row) # 行数
rowmax = ws.max_row + 1 # ループの range 境界値
for row in range(1, rowmax): # 先頭行から最終行まで
ws.row_dimensions[row].height = 18
for col in range(1, 3): # 行・列 (セル) 毎に配置属性を設定
ws.cell(row = row, column = col).alignment = aligment1
# Excel Book の保存・クローズ
wb.save(sys.argv[1])
wb.close()
本プログラムの実行の様子を以下に示す。生成された Excel ブックは図 5 のとおりである。フォント (メイリオ),漢字及びそれに対する Unicode コードポイントの列幅 (それぞれ 6,12),行高 (18),配置 (中央揃え) が,それぞれ ( ) 内の属性に変更されている。
$ ./adjustxlsx.py jisx0213-extarea-tbl.xlsx * adjustxlsx.py: sheet: jis0213-win attribute setting * adjustxlsx.py: jis0213-win items: 303 $
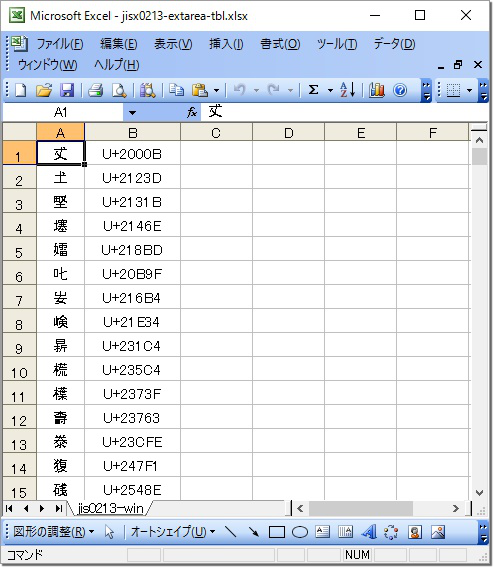
図 5. 属性変更後 Excel ブック: jisx0213-extarea-tbl.xlsx
参考資料
pandas,openpyxl の API の詳細は以下のドキュメントを参考にしていただきたい。
- pandas: pandas documentation
- openpyxl: openpyxl - A Python library to read/write Excel 2010 xlsx/xlsm files
筆者が学んだ Python3 の参考書をあげておく。
