私は受け取った電子メールを MHonArc というオープンソースソフトウェアで書庫化し,Web ブラウザでどこからでも閲覧できるようにしている(もちろん,閲覧者制限を付けている)。このソフトウェアは,元メールが HTML 形式のもの(以下「HTML メール」と称することにする)にも一応対応しているのだが,セキュリティ上の理由で外部参照画像,JavaScript などの転載を抑止しているため,メールによっては書庫化されたあとの内容がなんだかわけのわからない状態になることがある。HTML メールはたいてい業者から来るメールマガジンなので,私は別段困ることはない。
HTML メール
古くからインターネット電子メールを使っている人(多く昔からの UNIX ユーザ)は HTML メールを忌み嫌っているものである。パワーユーザが集まり長らく運用されて来たメーリングリストには「HTML メール投稿禁止」を subscribe の条件にしているものが多い。HTML メールは画像挿入,多様なフォント・色などにより華やかに出来る一方,余計な情報量が増え,かつセキュリティホールとなり易いからである。そもそも,電子メールは必要最小限の要件を情報リテラシーに則って手短かに伝える手段だったのである(電報に毛の生えたレベルといってもよいと思う)。ところが Microsoft Windows 付属のメールソフト Outlook が標準で HTML 形式でメールを作成するようになっているからか,いまや HTML メールが知らず知らずのうちに蔓延してしまう事態になっている。かくして Microsoft は口うるさい古狸 UNIX ユーザから蛇蝎のごとく嫌われる所以になっている。ま,俺にとっては別にどってことないんだけど。時代が変わったというだけのこと。
それはさておき,今日ちょっと,過去にロシアのインターネットマガジンサイト Ozon から来た HTML メールの内容が確認したくなり,メールメッセージから HTML 本体部分を分割して通常の HTML に復元する作業を行った。
MIME
ロシア語のような欧州の 8bit 文字コード(注)を使用する言語テキストを電子メールにエンベロープする際,MIME
たとえば,メールソフトでメール件名に「Новинки серии "Литературные памятники"」とロシア語表示されているものは,実際送られて来たメールの生のファイルでは,これは「Subject: =?windows-1251?
さらに,ロシア語 HTML メールの場合,多く,本文の HTML は
Content-type: text/html; charset=windows-1251 Content-Transfer-Encoding: quoted-printable
という符号化指定がされている。文字コード Windows-1251 はロシアでもっとも普及しているキャラクタコードセットである。そして,
よって,ロシア語 HTML メールをヘッダ部分と HTML 本体部分を分割して文字をデコードするには,それぞれ別の方法を採る必要がある。今回,Perl 言語で簡単な分割プログラムを書いた。ヘッダにある Subject 件名の文字列については Encode モジュールを,HTML 本体の quoted-
HTML メールの実際とその処理
実際の HTML メール(生のファイル)を見てみよう。
From news@ozon.ru Mon Jun 22 15:41:41 2015
Return-Path: <news@ozon.ru>
X-Spam-Checker-Version: SpamAssassin 3.4.1 (2015-04-28) on beatrice.yasuda.org
...
(中略)
...
From: "Ozon.ru - news" <news@ozon.ru>
To: isao@yasuda.homeip.net
Message-ID: <76d77630f1e948e180767c9989d0d474@ozon.ru>
Date: Mon, 22 Jun 2015 09:41:38 +0300
Subject: =?windows-1251?B?ze7i6O3q6CDx5fDo6CAiy+jy5fDg8vPw7fvlIO/g7P/y7ejq6CI=?=
MIME-Version: 1.0
Content-type: text/html; charset=windows-1251
Content-Transfer-Encoding: quoted-printable
<!DOCTYPE html>
<html>
<head>
<meta http-equiv=3D"Content-Type" content=3D"text/html; charset=3Dw=
indows-1251">
<meta http-equiv=3D"imagetoolbar" content=3D"no">
<title>=CD=EE=E2=E8=ED=EA=E8 =F1=E5=F0=E8=E8 "=CB=E8=F2=E5=F0=E0=F2=
=F3=F0=ED=FB=E5 =EF=E0=EC=FF=F2=ED=E8=EA=E8"</title>
=20
</head>
<body style=3D"BACKGROUND-IMAGE: url(http://mmedia=2Eozon=2Eru/graphics=
/subscribe/pl/150512-back-products-grey=2Egif); padding: 0; margin: 0" =
background=3D"http://mmedia=2Eozon=2Eru/graphics/subscribe/pl/150512-ba=
ck-products-grey=2Egif">
<table width=3D"100%" cellspacing=3D"0" cellpadding=3D"0" border=3D"0" =
class=3D"pad_null" style=3D"BACKGROUND-IMAGE: url(http://mmedia=2Eozon=2E=
ru/graphics/subscribe/pl/150512-back-products-grey=2Egif); padding: 0; =
margin: 0" background=3D"http://mmedia=2Eozon=2Eru/graphics/subscribe/p=
l/150512-back-products-grey=2Egif">
<tr>
<td>
...
(後略)
11 行目がメールヘッダ内にあるメールの件名,空行に続く 16 行目以降が HTML 本体である。後者のロシア語部分や一部記号が =XX に置き換わっていることがわかる。=(イコール)のような記号は =3D になっている。テキストの行途中で折り返した場合は行末に = が置かれ,スペースだけの空行の場合は =20 となっている。
このメールファイルを先頭から一行ずつ読んで,16 行目の <!DOCTYPE が現れたらそれ以降を HTML 本体として処理し,それ以前はヘッダ部として処理すればよい。内容をデコード(元のキリル文字に復元すること)しつつ,それぞれ content.
#!/usr/bin/perl -w
# Windows-1251 HTMLメールのメールヘッダと本文HTMLを分けてUTF-8で格納する
use Encode qw(encode decode);
use MIME::QuotedPrint;
open(HD, ">", "header.txt") || die "cannot open output file: $!\n";
open(HT, ">", "content.html") || die "cannot open output file: $!\n";
my $iflg = 0; # HTML本体のとき1, headerのとき0
my $concat = ""; # HTML連結用(行ごとでは編集できないことがあるため)
while (<STDIN>) {
$iflg = 1 if ($_ =~ /<!DOCTYPE/i);
if ($iflg) { # HTML本体
# quoted-printable をデコード
my $qpdecoded = MIME::QuotedPrint::decode_qp($_);
# デコードテキストを連結(あとで編集する)
$concat .= $qpdecoded;
} else { # ヘッダ部
# MIMEヘッダをデコード
my $hddecoded = Encode::decode('MIME-Header', $_);
# charset指定も書き換えておく
$hddecoded =~ s/charset=windows-1251/charset=UTF-8/i;
# UTF-8でファイルに出力
print HD Encode::encode('utf-8', $hddecoded);
}
}
close(HD);
# 連結HTMLデータ編集: charset 書き換え
$concat =~ s/charset=windows-1251/charset=UTF-8/i;
# HTMLデータをWindows-1251文字コードでデコード
my $t1251 = Encode::decode('cp1251', $concat);
# UTF-8にエンコードしてファイルに出力
print HT Encode::encode('utf-8', $t1251);
close(HT);
HTML 本体を一行読む毎ではなく,すべてのテキストを連結したあとに編集処理を行っているのは,本来一行で書かれていた HTML 行が MIME エンコードの過程で複数行に分割されており,たとえば,上記の例でいうと,charset=
さて,端末から上記プログラムで HTML メールを処理する。
% ls htmlmaildecode.pl* mail.txt % ./htmlmaildecode.pl < mail.txt % ls content.html htmlmaildecode.pl* header.txt mail.txt
デコード結果は次のとおり。
From news@ozon.ru Mon Jun 22 15:41:41 2015 Return-Path: <news@ozon.ru> X-Spam-Checker-Version: SpamAssassin 3.4.1 (2015-04-28) on beatrice.yasuda.org ... (中略) ... From: "Ozon.ru - news" <news@ozon.ru> To: isao@yasuda.homeip.net Message-ID: <76d77630f1e948e180767c9989d0d474@ozon.ru> Date: Mon, 22 Jun 2015 09:41:38 +0300 Subject: Новинки серии "Литературные памятники" MIME-Version: 1.0 Content-type: text/html; charset=UTF-8 Content-Transfer-Encoding: quoted-printable
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<meta http-equiv="imagetoolbar" content="no">
<title>Новинки серии "Литературные памятники"</title>
</head>
<body style="BACKGROUND-IMAGE: url(http://mmedia.ozon.ru/graphics/subscribe/pl/150512-back-products-grey.gif); padding: 0; margin: 0" background="http://mmedia.ozon.ru/graphics/subscribe/pl/150512-back-products-grey.gif">
<table width="100%" cellspacing="0" cellpadding="0" border="0" class="pad_null" style="BACKGROUND-IMAGE: url(http://mmedia.ozon.ru/graphics/subscribe/pl/150512-back-products-grey.gif); padding: 0; margin: 0" background="http://mmedia.ozon.ru/graphics/subscribe/pl/150512-back-products-grey.gif">
<tr>
<td>
...
(後略)
HTML をブラウザで確認する。
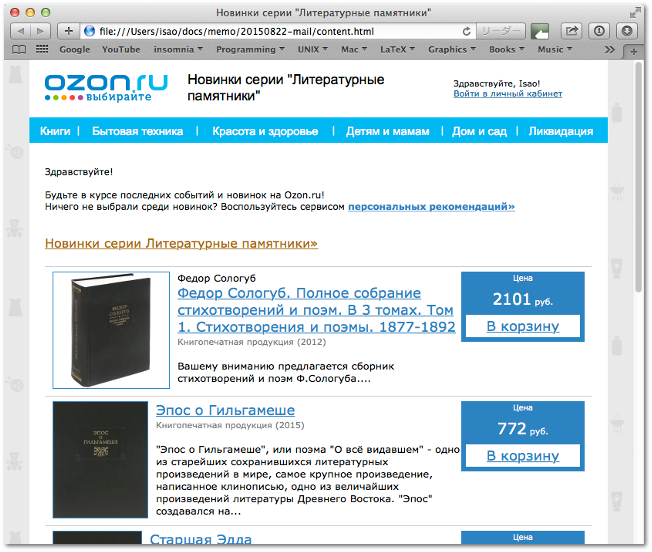
content.html をブラウザで表示