昨日,usconcord が動かないというメールを受け取った。2001 年に書いたロシア語電子コンコーダンス Web アプリケーションである。利用者が自分の研究対象であるコーパス(テキストファイル)に対し,指定したキーワード条件に基づいた KWIC (Key Word in Context) 表を作成し,コーパスにおける単語の現れ方を分析できる。
最近(とはいえ 2012 年 5 月に)拵えたプーシキン全集コンコーダンスとは異なり,見出語(名詞単数主格,動詞不定形など辞書の見出語形式)での集計や,キーワード条件への正規表現指定や近接隣接演算機能はサポートしていない。その代わり,メタ文字(*.)指定を使用して完全一致,中間一致,前方一致,後方一致といったトランケーションの可能な単項演算機能と,論理積(*),論理和(+),論理差(#),グループ指定(パーレン: (,) による演算優先順位の変更)の可能な二項演算機能をサポートしている。usconcord は “A # ((B + C * (D # E)) # F)”(A
サーバ OS(FreeBSD)のアップグレードやらなにやらで,私自身の関心の薄れた自作プログラムは放置状態になっていて,usconcord もいつのまにやら腐っていたようである。ソフトウェアとはそういうものである。そんなプログラムでも,研究のためのツールとして使ってくれる方がいて,「動かないよ」と指摘して下さった方もロシアの歴史的文書の分析でお使いいただいていたそうである。対象の古ロシア語を訳すに際して,同じ語の用例をつぶさに確認した上で訳語を決めるのに usconcord はたいへん有用だ,と言ってくれたのである。「こりゃ,直さなくっちゃ」。
もう十年以上論理を見直していない C,Perl,Shell Script からなるプログラム群。clang でコンパイルが通らないようになっていたりした。プー。追試したところ問題点は二つあった。
- ファイルアップロードがなされない
- コード変換でこける
Perl CGI モジュールによるファイルアップロード
ファイルアップロードがなされない問題については,Perl CGI モジュールの仕様が変わったようで,read メソッドを IO ハンドルに結びつけて発行しないとならなくなったようである。ファイルアップロードのサンプルコードとして,訂正後の Perl コードを参考までに掲載しておく。Web フォームの <input type="FILE" name="corpus" /> のところで指定したアップロード対象ファイルをサーバで読み取って(図 1. アップロード HTML 参照),ローカルに “プロセス番号.corpus” というファイル名で格納するコードである。以前のコードでは以下のハイライト行にある $io_handle がなかった。
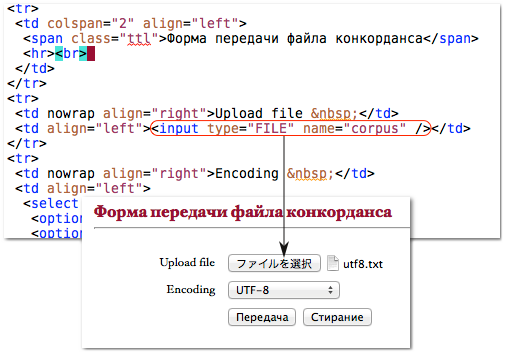
図 1. アップロード HTML
# CGI module
use CGI;
# Upload file handling
my $q = new CGI;
my $uplname = $q->param('corpus'); # Upload ファイル名
my $fh = $q->upload('corpus');
if (!$fh && $q->cgi_error) {
# エラー検知のときは即終了
userror("<P><B>$uplname - upload error: $q->cgi_error</B></P>\n");
print STDERR "* usupload error: $q->cgi_error\n";
exit 1;
}
my $wfile = ""; # アップロードされたファイルの内容を溜め込むエリア
if (defined $fh) {
my $io_handle = $fh->handle; # upload のファイルハンドル
my $buffer = ""; # read buffer
my $bufsz = 8192; # read buffer size
my $bytesread; # read で読み込んだバイト数
my $file_size = 0; # 蓄積したファイルサイズ
my $max_size = 2000000; # 最大ファイルサイズ制限値
while ($bytesread = $io_handle->read($buffer, $bufsz)) {
$wfile .= $buffer;
$file_size += $bytesread;
# ファイルサイズ制限のチェック
if ($file_size > $max_size) {
userror("<P><B>$uplname - file size too large " .
"(over $max_size).</B></P>\n");
print STDERR "* usconcord: file size too large " .
"(over $max_size).\n";
exit(1);
}
}
}
# write file
my $work_dir = "/tmp/usconcord";
open(COR, ">$work_dir/$$.corpus"); # プロセス番号.corpus
binmode(COR);
print(COR $wfile);
close(COR);
# エラー報告: エラーメッセージを埋め込んで HTML を出力する
sub userror {
my ($error) = @_;
# あとは割愛
}
X11 Ctext コード変換
二つ目の問題点は,X11 Ctext コード変換でこれまで使用していた coco というプログラムを,FreeBSD のバージョンアップの際にインストールし忘れていたため,コード変換でこけてしまっていたこと(というより,ファイルアップロードの問題でそこに至る前に停止していたんだけれど)。
coco とは,かの電総研が開発した多言語エディタ Mule の付属ソフトウェアとして公開されていた多言語文字コードユーティリティである。このソフトウェアの超個性的なところは X11 Ctext (Compound Text) を扱うことのできる点である。X11 Ctext について知っているのは,UNIX X Window System Ver. 11 の文字コードとよほどディープな付き合いをした方だと思う。X11 Ctext とは,Latin-1 (ISO 8859-1: 西ヨーロッパ言語),Latin-2 (ISO 8859-2: 東ヨーロッパ言語),Cyrillic (ISO 8859-5: キリル文字) など,ISO 標準となっている文字コード群を,エスケープシーケンスで切り替えることにより,既存の文字コードで多言語テキストを表現する符号化システムのひとつ,と言えるだろう。ベースになっているのは ISO 2022 国際標準である。X11 Ctext なんて Unicode 標準が当たり前になった現在は,マルチリンガル・コンピューティングにおける過去の遺産に等しい。(*)
% coco '*iso-8859-5*' '*ctext-unix*' < input > output
とやると,ISO 8859-5 でエンコードされたキリル文字テキスト input が,x'1B2D4C' という,キリル文字の始まりを示すエスケープシーケンスの付加された X11 Ctext output に整形される。
ところが,FreeBSD 9.2-RELEASE の ports で coco を導入しようとしたら,これを含む editors/mule-common はもはや存在しなかった。Mule 自体すでに Emacs 本体にマージされて久しく,mule-common パッケージはすでに obsolated ということらしい。coco はもうココにはないってか,などとオヤジギャグをひとりごちながら,どうするのかちょっと途方にくれたんだが,しばらくしてハッと思い出した。uso2022 なんていうウソくさい X11 Ctext 整形ツール(ISO 2022 の捩り)を二十年くらい昔に文字コードの勉強で書いたことを。文書も残してあったのである。
usconcord CGI から呼び出すスクリプトにある coco の部分を uso2022 に書き換えて,これで万事めでたくシステムが復旧した。
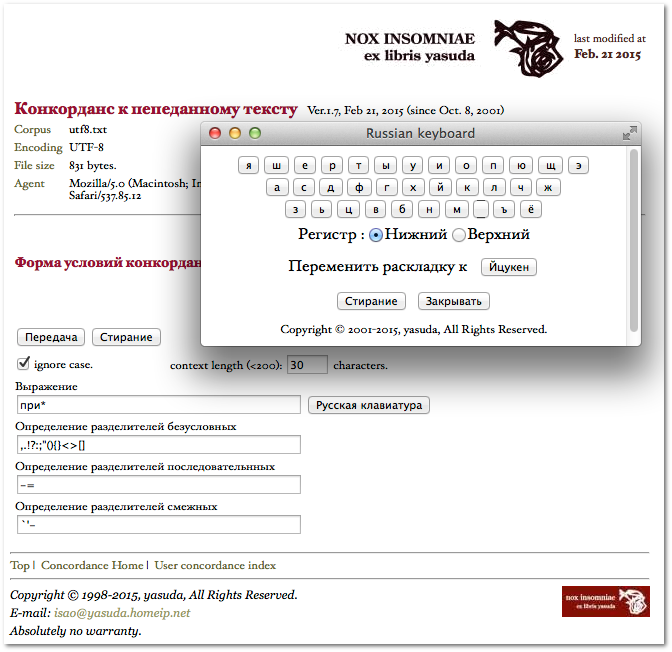
usconcord 条件入力画面
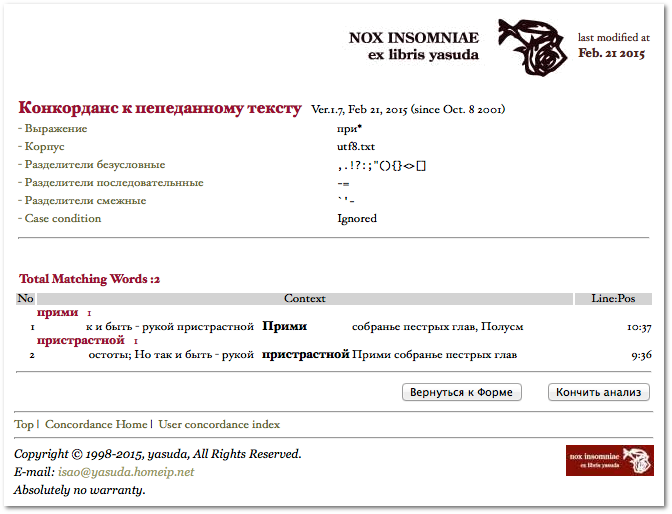
usconcord KWIC
参考文献

X11 Ctext について詳細に解説した数少ない文献(X Toolkit プログラミングマニュアル以外ではおそらく唯一の文献)をあげておく。GNU Emacs エディタ多言語拡張 Mule を開発した日本の誇る電総研の錚々たる研究者たちによって書かれた本の 1996 年初版である。私は結核病棟でヒマこいていた時期にこれを首っ引きになって研究し,usconcord の単語解析エンジン staslova と Ctext 変換ツール uso2022 を書いた。思い出深いコンピュータ本なんである。

プレンティスホール出版