多言語辞書 JMdict (Japanese Multi-lingual Electronic Dictionary) を Emacs 辞書検索ツール sdic で利用できるようにしてみた。その概略を示す。Emacs で使える和露,和仏,和独辞典をお探しの方の参考になれば幸いである。
先日 sdic をインストールし,英辞郎辞書を検索できるようにして以来,ロシア語辞書の電子データが手に入らないか探していた。フリーの露和辞典はなかなか見いだせなかったけれども,JMdict 日本語–多言語辞書を発見した。これは JMdict プロジェクトによってメンテナンスされている巨大な電子辞書である。ライセンスもフリーのようだ。ダウンロードした版で私が勘定したところ,13 万 4 千語を収録している。主に和独・和英がメインであるが,ロシア語,フランス語の訳も収録している。ロシア語訳が付与されている見出し語は,そのうち 6 千 7 百程度に過ぎない。それでもロシア語にはアクセントまで付加されていて感心した。
以下,手順を整理する。sdic,sufary のインストールについては,『英辞郎第四版を Emacs で使う』に纏めた。
- JMdict は,賢明にも,XML 形式 UTF-8 エンコードで配布されている。このため,別のフォーマットに変換したり,ロシア語訳がついているものだけ抽出するなど,加工が極めて容易になっている。そこで,sdic 形式に変換すれば,和独・露・仏・英辞典として sdic でも使えるだろうと考えた。XML から sdic へのフォーマット変換は,プログラムを書いてもよいが,お手軽に XSLT を使うことにした。
- FreeBSD,Linux の世界では,Apache XML プロジェクトによる Xalan XSLT プロセッサが有名である。ここでは,高速な C/C++ 版 Xalan-
c- 1. 10. 0 を使うことにする。Windows ユーザは Microsoft が無償配布している MSXML を利用することができる。Xalan("ザーラン" と呼ぶらしい)は,同じく Apache XML プロジェクトによる XML パーサ・ライブラリである Xerces-c を前提とする。FreeBSD ports でこれらパッケージを組込む。cd /usr/ ports/ textproc/ xalan-c && make install clean とするだけでよい。 - JMdict アーカイブをダウンロードし,解凍しておく。ここでは ~/tmp に JMdict ファイル名で XML 形式のファイルが解凍されたものとして説明する。
- 次に XSLT 変換のためのスタイルシートを準備する。これがいちばん厄介な作業であった。XML::Parser で Perl プログラムを書いたほうがラクなのかも知れなかった。JMdict には辞書として必要な様々な情報が付加されている(cf: JMdict 仕様)。私はこのなかから見出し,読み,品詞,反意語,参考情報,訳語(ドイツ語,フランス語,ロシア語,英語)を抽出し,sdic 形式に再編成することとした。sdic 形式は,見出し語を <H> タグで,検索語を <K> タグでそれぞれマークアップし,あとは一行内に情報をぶら下げるテキストである。見出し語は JMdict の漢字表記から採用し,同じ漢字表記と読みすべてを検索語としてタグ付けするようにした。こうしておくと sdic での検索を様々な表記で行い,見出し語を引くことができる。こうした仕様のために私が作成したスタイルシートを以下に掲げる。これを jmdict2sdic.
xsl ファイル名で格納する。 - Xalan XSLT プロセッサで XML から sdic 形式にフォーマット変換を行う。JMdict が巨大な上,Xalan はすべてのノードツリーをインコアで展開するため,処理には CPU,メモリコストもそれなりにかかる。IBM ThinkPad X40 Mobile Pentium-M 1.2GHz プロセッサで,実行時間約 7 分 15 秒,メモリ 300 MB を要した。メモリ(仮想記憶)不足にならないよう注意すべきである。
- 生成された sdic 形式辞書 jmdict.sdic は下図のようなイメージのはずである。
- 次に,jmdict.sdic を sdic 用ディレクトリに移動し,さらに高速化のため sufary インデックスを生成する。もし英辞郎の和英辞典も使いたいなら,JMdict とマージしてしまおう。
- Emacs 初期設定ファイル .emacs に以下を設定する。sdic-
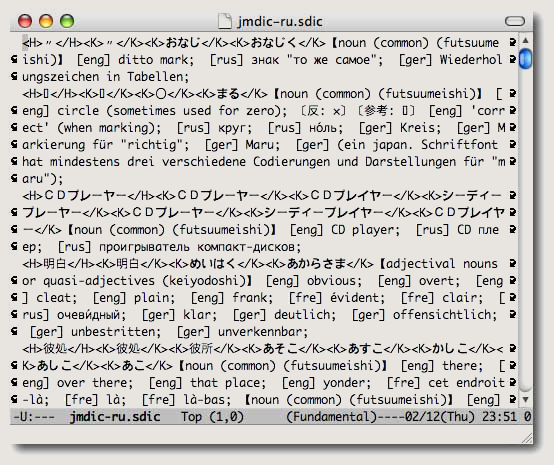
waei- dictionary- list 変数に対し,和英辞典として JMdict(jmdict.sdic)を指定する。和英辞郎マージ辞書の場合は waeijirou- jmdict. sdic である。 - 以上で JMdict 設定は完了である。sdic で検索してみた際のスナップショットを下図に示す。
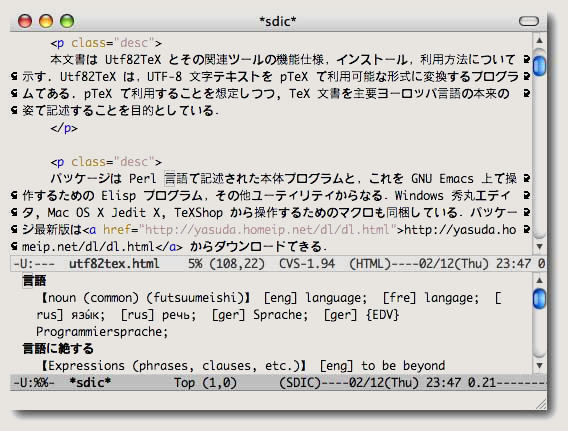
使い勝手において注意事項がひとつ。英文字を含む語,例えば「CDプレーヤー」などの語を引くとき,英文字は sdic 和英辞典検索では無視されるため,これで入力・検索してもヒットしない。この場合「シーディープレーヤー」と仮名表記で検索すればよい。これは,JMdict は様々な読みの表記を収録しており,上記スタイルシートではこれらをすべて検索対象語(<K> タグ)に設定するようにしているからである。だから「シーディープレイヤー」でも検索できる。検索結果では,見出し語(<H> タグ)として登録した「CDプレーヤー」が表示される。漢字表記の言葉も仮名で検索できるわけだ。「うたう」で検索すると,「歌う(sing, chanter, петь, singen, etc.)」,「謳う(express, énoncer, besingen, rühmen, etc.)」の訳語を調べることができる。
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text" encoding="UTF-8" />
<!--
JMdict XML -> SDIC 形式変換
JMdict XML タグ仕様
entry エントリ
k_ele 日本語漢字エレメント(表記の違いなど)
keb 日本語漢字
r_ele 日本語読み情報
reb 日本語読み
re_restr 日本語読み追加情報
sense 意味エレメント
pos 日本語品詞
xref 日本語関連語
ant 日本語反意語
gloss 多言語意味
xml:lan 言語 (英・独・仏・露ほか)
-->
<xsl:template match="JMdict">
<xsl:apply-templates select="entry" />
</xsl:template>
<xsl:template match="entry">
<xsl:text><H></xsl:text>
<xsl:value-of select="k_ele/keb | r_ele/reb" />
<xsl:text></H></xsl:text>
<xsl:for-each select="k_ele/keb | r_ele/reb | r_ele/re_restr">
<xsl:text><K></xsl:text><xsl:value-of select="." />
<xsl:text></K></xsl:text>
</xsl:for-each>
<xsl:for-each select="sense">
<xsl:if test="pos[not(.='')]">
<xsl:text>【</xsl:text><xsl:value-of select="pos" />
<xsl:text>】</xsl:text>
</xsl:if>
<xsl:if test="ant[not(.='')]">
<xsl:text>〔反: </xsl:text>
</xsl:if>
<xsl:for-each select="ant">
<xsl:value-of select="." />
</xsl:for-each>
<xsl:if test="ant[not(.='')]">
<xsl:text>〕</xsl:text>
</xsl:if>
<xsl:if test="xref[not(.='')]">
<xsl:text>〔参考: </xsl:text>
</xsl:if>
<xsl:for-each select="xref">
<xsl:value-of select="." />
</xsl:for-each>
<xsl:if test="xref[not(.='')]">
<xsl:text>〕</xsl:text>
</xsl:if>
<xsl:for-each select="gloss">
<xsl:text> [</xsl:text><xsl:value-of select="@xml:lang" />
<xsl:text>] </xsl:text>
<xsl:value-of select="." /><xsl:text>; </xsl:text>
</xsl:for-each>
</xsl:for-each>
<xsl:text>
</xsl:text>
</xsl:template>
</xsl:stylesheet>
% cd ~/tmp % Xalan -o jmdict.sdic JMdict jmdict2sdic.xsl
% su - m # mv jmdict.sdic /usr/local/share/dict # cd /usr/local/share/dict # cat jmdict.sdic waeijirou.sdic | sort > waeijirou-jmdict.sdic # 和英辞郎マージ # mkary jmdict.sdic # mkary waeijirou-jmdict.sdic # 和英辞郎マージ # ls -las jmdict* waeijirou-* ... 23972286 Feb 12 23:24 /usr/local/share/dict/jmdict.sdic ... 82669060 Feb 12 23:26 /usr/local/share/dict/jmdict.sdic.ary ... 167112343 Feb 12 23:25 /usr/local/share/dict/waeijirou-jmdict.sdic ... 508872436 Feb 12 23:28 /usr/local/share/dict/waeijirou-jmdict.sdic.ary #
;; sdic
(autoload 'sdic-describe-word "sdic" "単語の意味を調べる" t nil)
(global-set-key "\C-cw" 'sdic-describe-word)
(setq sdic-eiwa-dictionary-list
'((sdicf-client "/usr/local/share/dict/eijirou.sdic"
(strategy array))))
(setq sdic-waei-dictionary-list
'((sdicf-client "/usr/local/share/dict/jmdict.sdic" ;; JMdict
;'((sdicf-client "/usr/local/share/dict/waeijirou-jmdict.sdic" ;; +和英辞郎
(strategy array))))
(setq sdic-default-coding-system 'utf-8-unix)
;;
私は品詞情報に関して英語で付与された長たらしいそのままの情報を【 】に入れるようにスタイルシートを調整したけれども,一般的には日本語に変換して使うのがより便利だと思われる。その場合,XML ファイル冒頭に記述されている DTD のうち,実態参照定義を日本語で書直せば(つまり,<!ENTITY adj-i "adjective (keiyoushi)"> の "adjective (keiyoushi)" を "形容詞" あるいは "形" などとする),Xalan はそこから拾って本文に埋込んでくれるはずである。また,JMdict の XML そのものを眺めて,私が割愛した情報を取込むようスタイルシートをコーディングしてもよいだろう。
それにしても,この JMdict,おかしな日本語の見出しがかなりある。「誤った日本語」というのではなく「おま○こ」だの「Hな映画」だの「Tバック」だの,要するに俗語・卑語が満載で,かつ大阪弁などの方言も載っている。それだけ,ホットで実用的な電子辞書だと言うことが出来る(?)。外国人から見た日本文化というもののイメージが,こういうところにも現われているのではないだろうか。

本書は XSLT スタイルシートの書き方を,XPath 含めコンパクトに整理している。比較的安価なリファレンスである。XSLT プロセッサは主に Java 版の Xalan について触れていて,これは,Windows でも UNIX でも同一の操作が可能である。できることは C/C++ 版とほぼ同じであり,コマンドラインが異なるだけである。ただ Java 版は C/C++ 版よりもメモリを大食いし,その実行速度でも劣るかも知れない。