昨年,このブログで『Adobe Reader 8 Type1 フォント抽出失敗』の記事を書いた。この時は Ghostscript で作成した PDF では,また Adobe Reader 7 では問題なかったので,その後この問題を放置していた。ところが今日 (4日),素晴らしい多言語 LaTeX Web サイトを公開されている稲垣さんから,拙作 OldSlav 教会スラヴ語 LaTeX パッケージのドキュメントを Adobe Reader 8 で閲覧しようとしたら「埋め込みフォント『XXXX+
当時から SlavTeX Type1 フォントのエンコーディングに問題があるのではないかと思っていた。このフォントは В. Волович さんが SlavTeX パッケージを再編成する際に,А. Слепухин さんの SlavTeX オリジナル MF フォントから MF トレーサを使って生成したものである。今回,私は mftrace を用いて,フォントのエンコーディングに tex256.enc ファイルを参照するように指示して Type1 フォントを独自に生成してみた。
% mftrace --magnification=4000 --encoding=tex256.enc slav10 % t1binary slav10.pfa slav10.pfb
ってな具合。これを slav7 〜 slav24, islav7 〜 islav24 のすべてのフォントについて行うわけだが,ひとつひとつ実行するのは面倒なので,次のようなシェルスクリプトを書いた。これは,できるだけ大きな解像度で METAFONT 解析を試みつつ,pfb フォントと同時にマップファイルも生成する。
#!/bin/sh
# SlavTeX Type1 Fonts Generation for OldSlav
# using mftrace 1.2.5 and t1binary.
#
# 2008(c) isao yasuda, All Rights Reserved.
# Fonts Type
FFT="slav islav"
# Size
GENB="7 8 9 10 12 14 17 18 24"
# Encoding file
ENCF="tex256.enc"
# Map file
MAPF="oldslav.map"
# starting.
echo "* SlavTeX Type1 fonts generation for OldSlav started at `date`."
cp /dev/null $MAPF
# font list generation
FLIST=""
# type 1 list
for i in $FFT; do for j in $GENB; do FLIST="$FLIST $i$j"; done; done
# SlavTeX Computer Modern Type1 Fonts generation
for i in $FLIST
do
# When return code == 0 (mftrace normal end)
# - break and go to processing of the next fonts
# When return code != 0 (mftrace abnormal end)
# - decrease mag by 100 and retry mftrace
mag=4000
while [ $mag -ne 0 ]
do
echo "* $i try magnification=$mag --encoding=$ENCF."
mftrace --magnification=$mag --encoding=$ENCF $i
if [ $? -eq 0 ]
then
echo "* mftrace $i pfa gen succeeded at $mag magnification."
t1binary $i.pfa $i.pfb
echo "* t1binary $i pfb gen succeeded."
rm -f $i.pfa
echo "$i $i <$i.pfb" >> $MAPF
mag=0
else
mag=`expr $mag - 100`
fi
done
done
echo "* SlavTeX Type1 fonts generation for OldSlav ended at `date`."
これでできた Type1 フォントで古いものを置き換え,OldSlav ドキュメントを再組版してみたところ,Adobe Reader 8 でも問題なく出力できるようになった。ビンゴ! OldSlav パッケージにこの Type1 フォントを添付して公開しようと思っている。パッケージ修正はいささか時間がかかるので,とりあえず新しい SlavTeX Type1 フォント・アーカイブを暫定的に掲載しておく。これをダウンロード,解凍して,古い SlavTeX Type1 フォント ($TEXMF-LOCAL/fonts/type1/public/slavtex 配下にあると思う) と差換えればよい。
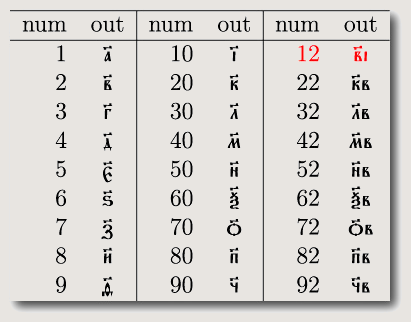
もうひとつ稲垣さんの指摘でわかったこと。OldSlav では教会スラヴ語の数値表現を自動的に出力する命令 (\slnum) をサポートしているが,稲垣さんによれば,\slnum の 10 台の数文字出力で 10 の位の数と 1 の位の数が逆転しているように思われるとのこと。しかし,А. Плетнева, А. Кравецкий 共著による教会スラヴ語教科書を再確認したところ,教会スラヴ語の数表現様式では 11 〜 19 の数字だけは文字を逆転させるのが規則である。よって,OldSlav 現状仕様の出力で正しいようである。私は OldSlav を作った際,この教科書で組版の正否を試験したのだが,この規則は読み落としていた。私も勉強になった。OldSlav の \slnum 命令は Слепухин さんの SlavTeX オリジナルコードを pTeX に忠実に移植しただけなので,要するに Слепухин さんが適切だったということなんだけど。
この 10 台の数値だけ位取りが逆転する規則は,考えてみれば別におかしくない。ロシア語では,たとえば 12 を десять (10) と два (2) の組み合わせではなく,двенадцать (12) という特別な語で示す (英語でも "ten two" ではなく "twelve" という独立した語である)。22 は двадцать два で 20 と 2 の結合となる。これに従えば,12 の表現において 2 の部分が 10 を表す文字より前に出る (две (2) - надцать (10)) のも納得できるわけである。
教会スラヴ語の数値表現を下図に示す。12 の例でだけ,10 の文字と 2 の文字がひっくり返っている。