Конкорданс к тексту А. С. Пушкина プーシキン全集見出語コンコーダンスの新しい版をリリースした。といっても,KWIC コンテキスト出力を指定文字数で切詰めるオプションをサポートしたことと,初期画面に説明文書タブが選択されるようにしただけである。例によって,この三連休での突貫工事であった。
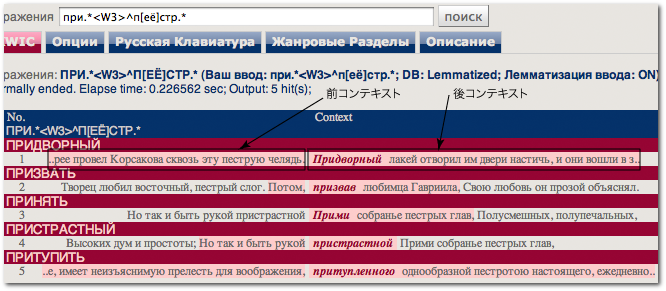
KWIC 前後コンテキスト
Unicode 文字列を指定文字数分抽出するために ICU C++ ライブラリのお試しを先日すませてあったので,目的とするプログラミングそのものの悩みは少なかった。icu::
/* -*- coding: utf-8; mode: c++; -*-
* Concordance to A. S. Pushkin's Works -
* emphword.cpp: ヒット語前後コンテクスト強調装飾
* - ヒットキーワード行,その前・後の三行,ヒット語位置情報,ヒット語前後テキスト
* 切詰め文字数をもとに,以下を行い,KWIC コンテキストを整形する。
* (1) キーワードをヒット行から抽出する。
* (2) キーワード前テキストを指定文字数で短縮する。
* (3) キーワード及び後テキストを指定文字数で短縮する。
* (4) ヒット行,キーワードに対しハイライト装飾を施し出力エリアにセットする。
* Copyright (C) 2012-2013, isao yasuda
*/
#include <boost/regex.hpp>
#include <boost/regex/icu.hpp>
#include <cstdlib>
// 引数
// - l0: ヒット行; l1: 前行; l2: 後行;
// - o1: 前コンテキスト編集結果; o2: ヒットキーワード+後コンテキスト編集結果;
// - pos: ヒット単語位置情報;
// - cprelen: 前コンテキスト最大長; caftlen: 後コンテキスト最大長 (今回追加)
void emphword(std::string& l0, std::string& l1, std::string& l2,
std::string& o1, std::string& o2, int pos,
int cprelen, int caftlen)
{
// (1) キーワードをヒット行から抽出する。
// 実体参照 <(<),>(>),"(") を一時的に記号に置換する
std::string bufo(l0);
boost::regex rp1("<");
boost::regex rp2(">");
boost::regex rp3(""");
bufo = boost::regex_replace(bufo, rp1, "<");
bufo = boost::regex_replace(bufo, rp2, ">");
bufo = boost::regex_replace(bufo, rp3, "\"");
// 単語ヒット行 (current) 編集バッファ
char* buf = new char[bufo.size()+1];
std::strcpy(buf, bufo.c_str());
// pos に基づいてヒットしたキーワードを取り出し ws に格納する
// - 正規表現 iterator で単語マッチを pos まで繰り返し,単語と位置を取得する
// - §†¼½⅓№ 以外に単語として扱うべき約物が corpus にない前提
boost::u32regex r(boost::make_u32regex("([§†¼½⅓№0-9\\-'\\w]+)"));
boost::utf8regex_iterator i(boost::make_u32regex_iterator(buf, r));
boost::utf8regex_iterator j;
int k = 0; // 行頭からの語数
std::string ws; // 強調すべきヒット語
int wpt; // その位置
while (i != j) {
if (k++ == pos) {
ws = (*i)[0]; // pos 番目の単語を取得
wpt = (*i).position(); // pos 番目の語位置を取得
break;
}
i++;
}
std::string s0 = bufo.substr(0, wpt); // ヒット語前テキスト
std::string s1 = bufo.substr(wpt + ws.size()); // ヒット語後テキスト
// ここから今回追加
// 指定文字数でコンテクスト長を制限
// std::string を icu::UnicodeString に変換
icu::UnicodeString uspre = icu::UnicodeString::fromUTF8(s0);
icu::UnicodeString usaft = icu::UnicodeString::fromUTF8(s1);
icu::UnicodeString usws = icu::UnicodeString::fromUTF8(ws);
icu::UnicodeString usl1 = icu::UnicodeString::fromUTF8(l1);
icu::UnicodeString usl2 = icu::UnicodeString::fromUTF8(l2);
// (2) キーワード前テキストを指定文字数で短縮する。
// 前テキスト編集 (切詰長 cprelen が 0 の場合は無制限=何もしない)
if (cprelen > 0) {
int s0len = uspre.length(); // 前テキスト文字数
if (s0len > cprelen) {
uspre = uspre.tempSubString((s0len - cprelen), cprelen);
uspre = ".." + uspre;
usl1 = "";
} else {
if ((usl1.length() + s0len) > cprelen) {
usl1 = usl1.tempSubString
((usl1.length() - (cprelen - s0len)), (cprelen - s0len));
usl1 = ".." + usl1;
}
}
}
// (3) キーワード及び後テキストを指定文字数で短縮する。
// 後テキスト編集 (切詰長 caftlen が 0 の場合は無制限=何もしない)
if (caftlen > 0) {
int s1len = usaft.length(); // 後テキスト文字数
int aftmax = caftlen - usws.length(); // ヒット語除く最大後テキスト文字数
if (s1len > aftmax) {
usaft = usaft.tempSubString(0, aftmax) + "..";
usl2 = "";
} else {
if ((s1len + usl2.length()) > aftmax) {
usl2 = usl2.tempSubString(0, (aftmax - s1len)) + "..";
}
}
}
// icu::UnicodeString を UTF-8 符号化して std::string に格納
std::string s0t; s0 = uspre.toUTF8String(s0t);
std::string s1t; s1 = usaft.toUTF8String(s1t);
std::string l1t; l1 = usl1.toUTF8String(l1t);
std::string l2t; l2 = usl2.toUTF8String(l2t);
// ここまで今回追加
// <,>," を実体参照に戻す
boost::regex ro1("<");
boost::regex ro2(">");
boost::regex ro3("\"");
s0 = boost::regex_replace(s0, ro1, "<");
s0 = boost::regex_replace(s0, ro2, ">");
s0 = boost::regex_replace(s0, ro3, """);
s1 = boost::regex_replace(s1, ro1, "<");
s1 = boost::regex_replace(s1, ro2, ">");
s1 = boost::regex_replace(s1, ro3, """);
// (4) ヒット行,キーワードに対しハイライト装飾を施し出力エリアにセットする。
// 強調表示挿入文字列
std::string lopen = "<span class=\"hl\">"; // ヒット行ハイライト開始
std::string lclos = "</span>"; // ヒット行ハイライト終了
std::string eopen = "<em class=\"hit\">"; // ヒット語ハイライト開始
std::string eclos = "</em>"; // ヒット語ハイライト終了
// 強調装飾を施し,pre l1 - cur l0 - aft l2 を連結し,o1 (前), o2 (後) にセット
if (pos) {
// ヒット語がヒット行先頭以外の場合
o1 = l1 + " " + lopen + s0 + lclos;
o2 = eopen + ws + eclos + lopen + s1 + lclos + " " + l2;
} else {
// ヒット語がヒット行先頭 (pos が 0) の場合
o1 = l1 + " " + lopen + s0 + lclos;
o2 = lopen + eopen + ws + eclos + s1 + lclos + " " + l2;
}
// 動的確保文字列領域を解放
delete [] buf;
}
ところが,コンコーダンス・プログラムの Web 基盤として使っている Wt C++ Web Toolkit を今回ついでに 3.3.1 にバージョンアップしたのだが,こちらの動作仕様が変ってしまっていたことで躓いた。
Wt::WTabWidget で生成したタブのコンテンツが初期画面ですべて同じタブ画面に出力されてしまう。これ,バグじゃないかと思う。でも,成り行きでもう昔の版に戻すのも憚られたので,いろいろ試した結果,すべてのタブについて Wt::