プーシキン・コンコーダンス Web サービス Конкорданс к тексту А. С. Пушкина に全コーパスを搭載した。これは,ロシアの文学電子テキストサイト Русская виртуальная библиотека (RVB) から А. С. Пушкин. Полное собрание сочинений в десяти томах. = 10 巻本プーシキン全集の HTML テキストを Wget でダウンロードし,コーパスとして加工したものに基づいている。RVB のテキストは 1959 年にモスクワで出版されたアカデミー版プーシキン全集に従って電子化されたものである。
RVB HTML のテキスト誤り(主にキリル文字を同形のラテン文字で誤植したもの。あまりの夥しさにびっくりした)を訂正し,プーシキンテクスト以外の校訂者テクスト等の余計な部分を削った。作品テクストについては,タイトル,章・節名を外し,プーシキンによる注,序文のほか,エピグラフやプーシキンによる他の作家からの引用は取り込んである。KWIC コンコーダンス表から該当テクストを表示するために,行・パラグラフごとに HTML ID 要素として独自に行 ID を付加した。Perl HTML::Parser モジュールによって,RVB HTML データをタグ解析した上で抽出したプーシキン・テクストに,ジャンルID,作品番号(作品名データベースのキーであると同時に Web ページのファイルベース名でもある),行番号,行ID を付与して,コーパスを作成した。
共有メモリへのデータ構築,ロシア語形態素解析ライブラリ Lemmatizer の活用(出現形からの見出語解析),ロシア語正規表現操作,UTF-8 文字列操作(大文字変換など)等々,C/C++ 言語ノウハウにかなり悩まされたのだけれど,今回何より時間を掛けたのはコーパスの準備であった。サービス用の C++ プログラムは 1500 行にも満たないが,コーパス編集のために試行錯誤で書いた Perl プログラム,シェルスクリプトはその 2 倍にはなると思う。テキストエディタ上で手動でしこしこ手直ししたりもしなければならなかった。思い立って 3 年くらいだろうか,ようやく目的のことができるまで漕ぎ着けたという感がある。
前回からの改変を整理しておく。プーシキン全集コーパス(ただしヴァリアントはまだ未収録である)を掲載するにあたり,コンコーダンス生成対象ジャンルを選択できるようにした。そして,どの作品がジャンルに属しているのかが一覧できる Web ページを準備し,そのリンクを設置した。見栄えの変更を少々行った。改めて,使い方を説明以下に説明する。
プーシキン・コンコーダンス・ページは http://yasuda.
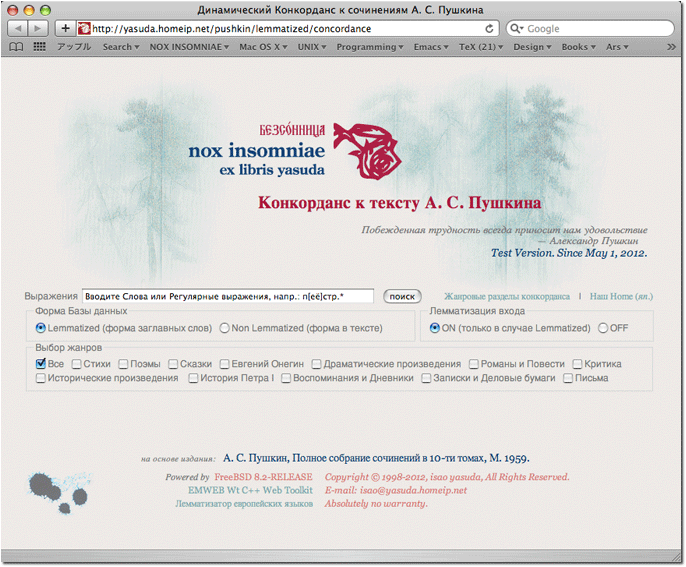
図 1. 初期画面
Вводите Слова или Регулярные выражения, напр.: п[её]стр.* と書かれたテキストボックスに,KWIC コンコーダンス表を生成したい単語条件を入力する。そして,オプションのチェックボックスでジャンルを選択する。初期状態では все がチェックされている。ジャンルにどの作品が属しているかは実行ボタン右にある Жанровые разделы конкорданса ページ(図 2.)で確認できる。このページのジャンル(Стихитворения 等)の左側にある番号は,ジャンルID(00-12)である。
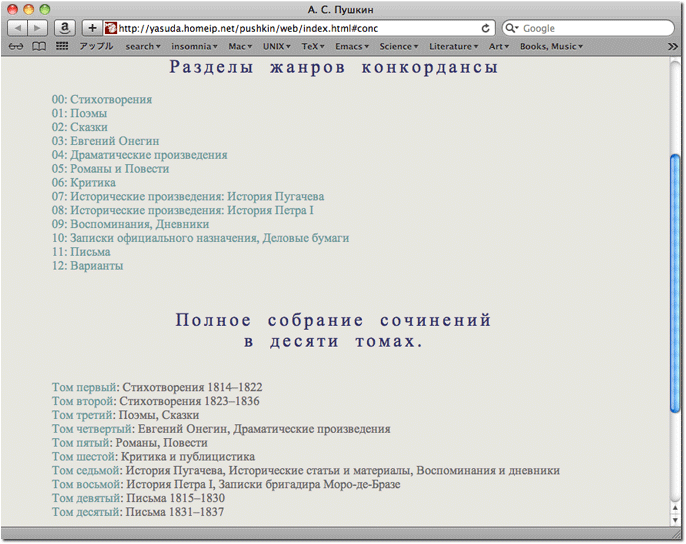
図 2. ジャンル分類ページ
単語条件は空白文字で区切って複数指定できる。単語の見出語に完全一致する形式で入力してもよいが,正規表現を用いて条件に幅をもたせることをお勧めする。メタ文字 — 任意の一文字にマッチする . ピリオド,前置文字の 0 個以上にマッチする * アスタリスク,指定した文字のどれかにマッチするグループを形成する [ ],語頭,語末にそれぞれマッチする ^$ 等 — を組み合わせて単語条件を表現するのである。メタ文字が一つも含まれないと完全一致条件とみなす。
この正規表現のマッチングには Boost.
単語条件には近接隣接演算指定ができる。これは目的とする語について別のある語と離れている距離が,指定した語数,行数の範囲内であるという条件である。単語1<W|L数値>単語2 の書式である。両端の単語1, 2 は正規表現でもよい。例えば,СЛОВО1<W10>СЛОВО2 のように空白文字を入れずに書くと,СЛОВО2 との距離が 10 語以内の СЛОВО1 を探索して KWIC を生成する。W の代わりに L を指定すると行条件となる。ここで行とは詩の場合は詩行だが,散文についてはパラグラフと考えてよい。
近接隣接演算 пестр.*<W5>приня.* 指定を行った例を図 3. に示す。
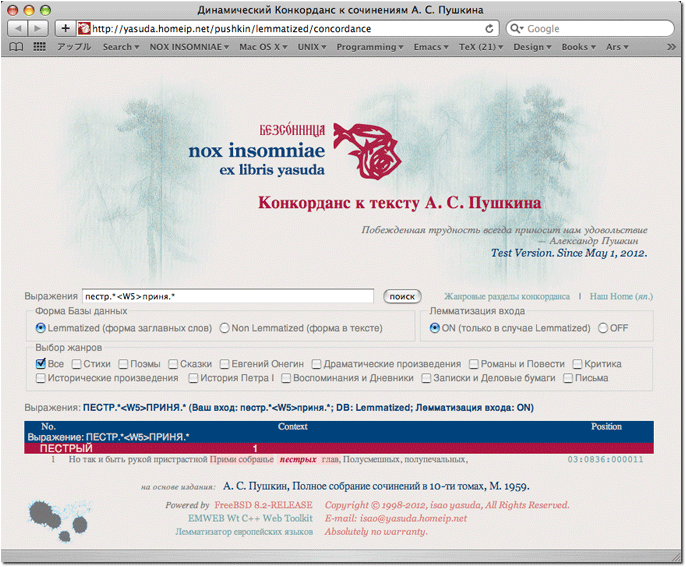
図 3. 近接隣接演算結果
приня.*(приня という部分文字列)を含む単語から 5 語以内に出現する пестр.*(пестр という部分文字列を含む単語)を探索している。結果は ПЕСТРЫЙ 1 件だったことが赤地の行でわかる。それに続いて,ヒットした語の行及び前後行からなるコンテキストが表示される。певтрых が Прими の 2 語あとに出現していて,条件に合致している(прими の見出語は принять なので приня.* の条件でヒットするのである)。ヒットした語は赤ボールドイタリック体で,ヒットした行は薄紅背景で強調される。
コンテクスト右端に表示されているのは位置情報である。ジャンルID:作品番号:出現行 の形式である。位置情報にカーソルを合わせると,その作品名がポップアップされる。位置情報にはリンクが設置されており,クリックすると,当該作品の Web ページのヒットした行を直接参照することができる(図 4.)。作品番号は本システム内の便宜上のものに過ぎない。
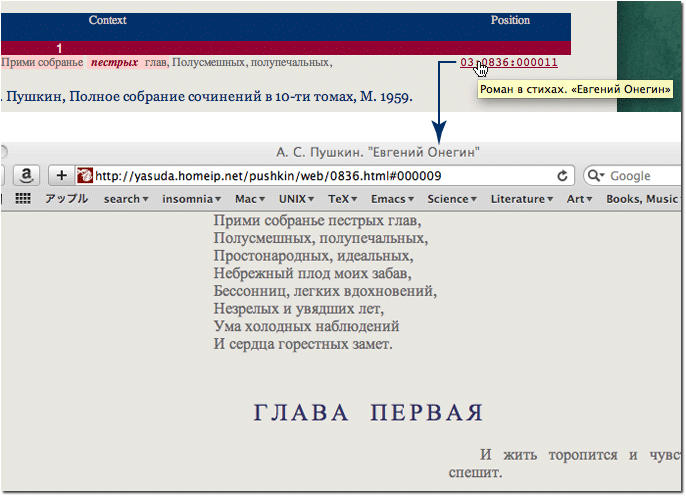
図 4. 位置情報リンク
オプション Форма Базы данных は,指定単語条件の探索を見出語形で行う(見出語形モード)か出現形で行う(出現形モード)かの指定である(図 5.)。Lemmatized (форма заглавных слов) は Lemmatizer によって見出語に正規化した語形に出現単語を纏めて KWIC コンコーダンス表を作成する。これが初期状態で ON になっている。見出語形式では,入力にも見出語を表現する条件式を指定しないとヒットしない。単語の変化形を完全一致で入力しても,データベースのキーが見出語形であるためである。見出語での整理にこだわらず出現形そのもので探索したいのならば Non Lemmatized (форма в тексте) を選択すればよい。

図 5. 見出語形モード/出現形モード選択オプション
オプション Лемматизация входа は,データベースを探索する前にユーザ入力を見出語形式に変換するか否かの指定である(図 6.)。この指定は見出語形式の場合のみ参照される。前述のとおり,見出語モードの場合,例えば пестрых という形容詞複数生格を入力してしまうと見出語形ではないのでヒットせず無意味である。このオプションを ON (только в случае Lemmatized) にしておくと,システムがユーザ入力を見出語形に変換してからデータベース探索を行う。ただし正規表現メタ文字があるとこの変換はなされない。オプションが OFF だとユーザ入力のまま探索する。初期状態は ON である。

図 6. 入力見出語変換選択オプション
本システムにおける見出語への正規化は,Lemmatizer: Лемматизатор европейских языков を用いている。ロシア語の見出語自動生成は複数の選択肢がある場合が多く,文脈に応じた完璧な見出語選定は不可能である。本システムにおける見出語選定方法については,本ブログ記事 Russian Word Lemmatizer を参照いただきたい。
使い方概略は以上である。ヴァリアント以外のあらゆるプーシキン・テクストをベースにしている。考えられる限り最大限の高速化を図ったつもりである。プーシキン研究者のお役に立てることを願っている。ご意見,ご要望があればぜひ電子メールでご連絡いただきたい。ただし,当座は試験的運用として一般公開するが,サーバ・アタックが最近あまりにも多いので,いずれセキュリティ防御を施して限定公開とするつもりである。
今回の改修で,機能的にはほぼ目的としたところまでできた。今回,Web の画面構築,バックエンドのビジネスロジックなど,すべてを Wt C++ Web Toolkit を使って実現した。Apache2 とのインタフェースでは FastCGI モジュールを利用して高速化を図っている。あとは閑をみて,ロシア語疑似キーボードや使用説明等のタブを設置したいと考えている。Wt C++ Web Toolkit には,この実現を支援する魅力的な機能が満載なんである。
付記:その後,ロシア語疑似キーボード,英文使用説明をビルトインしたタブインタフェース版が完成した。オプション設定もそれ用のタブに纏めた。大量ヒット抑止の工夫も入れた。