Boost Interprocess を用いて,共有メモリ Shared Memory に map を構築し,プロセス間共有を実現する方法について記事を書いた。コンコーダンスの実装でもこの方法が使えると思ったが,ちょっと甘かった。コーパスから切り出した単語情報ノードは,単語(キー)とその出現件数,単語の出現位置情報リストから構成される設計としたが,map のぶら下がり情報(キーで引かれるデータ)がこのように複雑なデータ構造をもつ class だと,いろいろ試験的にプログラムを書いて試したところ,うまく共有メモリ上に構築できなかった。おそらく私の Boost の使い方がまずいのだと思うが,Boost の膨大なマニュアルを調べ,試験コードを書いて確かめるのにも疲れた。
そこで Boost Interprocess が提供している map,list などのコンテナに自作 class を格納するのを諦め,共有メモリ上に単語情報二分木 Binary Tree を自力で構築することにした。std::string や allocator の内部管理処理(内部カウンタ管理等)のオーバーヘッドがない分,高速化も期待できる。
二分木データ構造(Binary Tree)
コーパスから単語を切り出すつど単語をキーとして,共有メモリ上のツリーにノードを繋げて行く。キーを比較し一致したら単語出現カウンタをインクリメントし,単語出現位置情報を追加する。キーより辞書順で小さければ当該ノードよりも左,大きければ右のノードにアクセスする。これをルートノード(最初に登録したもの)からはじめて,左右ノードがなくなる(ポインタが NULL になる)と新しくノードを生成する。これらを再帰的に(芋蔓式に)繰返し,ツリーを構築する。参照もまったく同様に再帰的に処理を行う。
処理方式はこのようなものである。ノードには log N 対数計算量でアクセスでき,つまりはデータ件数が 10000 倍になっても 3 倍程度しか性能が低下しない。このアルゴリズムは辞書管理や連想配列の常套的方式になっている。例えば「Мой дядя самых честных правил, Когда не в шутку занемог」というテクストを入力し,単語二分木を作ると図のようなデータ構造になる(まったく関係ないが,プーシキンの『エヴゲーニイ・オネーギン』のこの書き出しは,二分木として恐ろしく均斉が取れていて — ノードへのアクセス効率が高い — 驚く。もしかすると,プーシキンは文字構成のバランスにも気を配ったのかも知れない)。
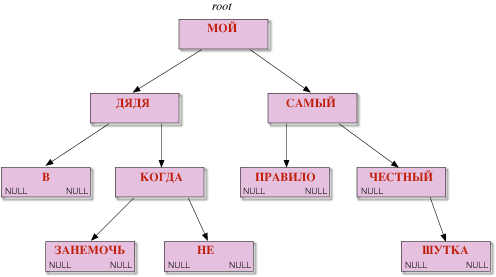
Binary Tree data structure 二分木データ構造
共有メモリ二分木構築: 配置 new 演算子と offset_ptr アクセス
共有メモリ上にこの二分木データ構造を構築するのに,C++ 配置 new 演算子(placement new:指定位置にオブジェクトを生成する)によって,確保した共有メモリ領域にあらゆるデータを明示的に割り付けて行く設計とした(フリーストアから自動的に領域を確保する通常の new 演算子ではダメである)。共有メモリの確保・解放とその先頭アドレスの取得において Boost Interprocess 提供関数を利用する以外は,自力で割り付けて行くのである。データを割り付けるつど,消費したメモリサイズだけアドレスを再計算し,ポインタを更新しなければならない。単語情報ノードは,単語文字列,出現回数カウンタ,及び出現位置情報(ジャンル番号,作品番号,HTML 行 ID,行番号,行先頭からの相対位置,作品先頭からの相対位置)リンクリストからなるものとし,これらを構成するデータオブジェクト,ポインタ(アドレスデータ)すべてを位置指定で共有メモリ領域に格納して行く。
このとき,注意しなければならないのは,共有メモリ内のデータには通常のポインタ(仮想記憶アドレス)を格納できないということである。文字列データを格納したいとき,その仮想記憶アドレスを指す char* ポインタを共有メモリ内に置くのは,不可なのだ。当該プロセスからのみ使う場合はこの制約はない。けれども,構築した二分木を他のプロセスからもアクセスするという本来的目的には使えない。何故なら,共有メモリはバインドされる仮想記憶アドレスがプロセスによって異なる場合があるため,別のプロセス(自己の仮想記憶のアドレス・ポインタを格納したプロセスとは別のプロセス)がそのポインタの指すアドレスを参照すると,とんちんかんなメモリ領域にすっとんで,記憶保護例外(segmentation fault)で異常終了したり,無関係のデータを取得したりしてしまうからである。
では,共有メモリ内にポインタを格納して他のプロセスからも共有したいときにどうするか。オフセット・ポインタ offset pointer を使うのである。要するに,仮想記憶アドレスではなく,あるアドレスからの相対位置(オフセット)をポインタとして格納し,アクセスする際にプロセス内での実際の仮想記憶アドレスを計算してポイントするのである。Boost Interprocess は,このための便利なポインタ class offset_ptr
C++ ソースコード
上記の制約を踏まえ,単語情報二分木・共有メモリ構築サーバプログラム,二分木アクセスクライアントの,二つの簡単なプロトタイプを書いた。前者は,コーパステクストを読んで,Lemmatizer で見出語解析を行い,見出語をキーとした単語情報ノードからなる二分木を共有メモリに構築する。格納するポインタはすべて offset_ptr
/* -*- coding: utf-8; mode: c++; -*-
* Lemmatized Word Tree, Corpus common header
* 2012(c) isao yasuda.
*/
#ifndef SHARED_MEMORY_CORPUS_WORD_TREE
#define SHARED_MEMORY_CORPUS_WORD_TREE
#include <boost/interprocess/managed_shared_memory.hpp>
#include <boost/interprocess/allocators/allocator.hpp>
#include <boost/interprocess/containers/string.hpp>
#include <boost/interprocess/containers/vector.hpp>
#include <boost/interprocess/offset_ptr.hpp>
#include <iostream>
#include <fstream>
#include <sstream>
#include <csignal>
// Typedefs of allocators and containers
using namespace boost::interprocess;
typedef managed_shared_memory::segment_manager segment_manager_t;
typedef allocator<char, segment_manager_t> char_allocator;
typedef basic_string<char, std::char_traits<char>, char_allocator> char_string;
typedef allocator<char_string, segment_manager_t> string_allocator;
typedef vector<char_string, string_allocator> shm_vector;
// shared memory constants
static const char* SHMTREE = "ShmWordTree"; // 共有メモリ名 Word Tree
static const char* SHMCRPS = "ShmCorpus"; // 共有メモリ名 Corpus
static const int SHMTRSZ = 1024 * 1024 * 10; // 共有メモリサイズ Word Tree
static const int SHMCRSZ = 1024 * 1024 * 10; // 共有メモリサイズ Corpus
static const int MNGSIZE = 256; // 管理領域(使用不可エリア)サイズ
static char* sp; // 共有メモリ内アロケーションポインタ
// 位置情報クラス
class wpos {
int genre; // ジャンル
int fname; // ファイル名
int linid; // 行 id
int linno; // 行通番
int linps; // 行内出現アドレス(行先頭からの相対位置)
int wdpos; // 単語出現アドレス(作品先頭からの相対位置)
offset_ptr<wpos> next; // 次の位置情報への相対ポインタ
friend class tree;
public:
wpos(int ge, int fn, int id, int ln, int lp, int wp)
: genre(ge), fname(fn), linid(id), linno(ln), linps(lp), wdpos(wp),
next(NULL)
{}
void printwpos(); // 位置情報出力
};
// 位置情報出力: 全位置情報を芋蔓式に出力する
void wpos::printwpos() {
if (this != NULL) {
std::cout << genre << ":" << fname << ":" << linid << ":"
<< linno << ":" << linps << ":" << wdpos << "; ";
next->wpos::printwpos();
} else {
std::cout << "\n";
}
}
// 二分木クラス
class tree {
private:
// 単語ノードクラス
class node {
offset_ptr<char> word; // 単語への相対ポインタ
int counter; // 出現回数
offset_ptr<wpos> fpos; // 最初の位置情報への相対ポインタ
offset_ptr<wpos> lpos; // 最後の位置情報への相対ポインタ
offset_ptr<node> right; // 右ノードへの相対ポインタ
offset_ptr<node> left; // 左ノードへの相対ポインタ
friend class tree;
};
// ルート
offset_ptr<node> root;
// ノード登録
void enter_node(offset_ptr<node>& node, const std::string& word,
int gi, int fi, int ii, int li, int pi, int wi);
// ノード出力
void print_node(offset_ptr<node>& top);
// ノード検索
void find_node(const std::string& word, offset_ptr<node>& top);
public:
tree() { root = NULL; }
// ツリー登録
void enter_tree(const std::string& new_word,
int gi, int fi, int ii, int li, int pi, int wi) {
enter_node(root, new_word, gi, fi, ii, li, pi, wi);
}
// ツリー出力
void print_tree() {
print_node(root);
}
// ツリー検索
void find_tree(const std::string& word) {
find_node(word, root);
}
};
// ノード登録:
void tree::enter_node(offset_ptr<node>& new_node, const std::string& new_word,
int gi, int fi, int ii, int li, int pi, int wi)
{
// 登録単語サイズ
size_t sz = new_word.size() + 1;
// ノードポインタが NULL の場合: 新規登録
if (new_node == NULL) {
// 新しい node を生成
new_node = new(reinterpret_cast<node*>(sp)) node;
sp += sizeof(node); // ポインタ更新
// 左右ポインタ初期化
new_node->left = NULL;
new_node->right = NULL;
// 単語登録
new_node->word = new(sp) char[sz];
std::strcpy((char*) sp, new_word.c_str());
sp += sz; // ポインタ更新
// カウンタ初期化
new_node->counter = 1;
// wpos 初期登録
new_node->fpos = new(reinterpret_cast<wpos*>(sp))
wpos(gi, fi, ii, li, pi, wi);
new_node->lpos = new_node->fpos;
sp += sizeof(wpos); // ポインタ更新
return;
}
// offset_ptr を char* に変換
char* wp = (new_node->word).get();
// 既登録の単語と一致した場合: カウンタをアップし,位置情報を追加
if (std::strcmp(wp, new_word.c_str()) == 0) {
new_node->counter += 1;
(new_node->lpos)->next = new(reinterpret_cast<wpos*>(sp))
wpos(gi, fi, ii, li, pi, wi);
new_node->lpos = (new_node->lpos)->next;
sp += sizeof(wpos); // ポインタ更新
return;
}
// 既登録単語より辞書順で後なら右ノードへ,前なら左ノードへ
if (std::strcmp(wp, new_word.c_str()) < 0)
enter_node(new_node->right, new_word, gi, fi, ii, li, pi, wi);
else
enter_node(new_node->left, new_word, gi, fi, ii, li, pi, wi);
}
// ノード出力
void tree::print_node(offset_ptr<node>& top)
{
// ノードポインタが NULL ならそこで終了
if (top == NULL) return;
// 左ノードを出力
print_node(top->left);
// 現ノードを出力
char* wp = (top->word).get(); // offset_ptr を char* に変換
std::cout << wp << " " << top->counter << " ";
(top->fpos)->printwpos();
// 右ノードを出力
print_node(top->right);
}
// ノード検索
void tree::find_node(const std::string& tword, offset_ptr<node>& tnode)
{
// ノードポインタが NULL ならそこで終了
if (tnode == NULL) return;
// offset_ptr を char* に変換
char* wp = (tnode->word).get();
// 指定単語に一致したら現ノードを出力
if (std::strcmp(wp, tword.c_str()) == 0) {
std::cout << wp << " " << tnode->counter << " ";
(tnode->fpos)->printwpos();
return;
}
// 既登録単語より辞書順で後なら右ノード,前なら左ノードを検索
if (std::strcmp(wp, tword.c_str()) < 0)
find_node(tword, tnode->right);
else
find_node(tword, tnode->left);
}
// シグナル・ハンドラ
void term(int n) {
std::cout << "Signal caught " << n << "\n";
exit(1);
}
// 共有メモリを開始前と終了後に削除する remover
struct shm_wtree_remove
{
shm_wtree_remove() {
shared_memory_object::remove(SHMTREE);
}
~shm_wtree_remove(){
std::cout << "Word Tree Shared Memory Deconstruction.\n";
shared_memory_object::remove(SHMTREE);
}
};
struct shm_corpus_remove
{
shm_corpus_remove() {
shared_memory_object::remove(SHMCRPS);
}
~shm_corpus_remove(){
std::cout << "Corpus Shared Memory Deconstruction.\n";
shared_memory_object::remove(SHMCRPS);
}
};
#endif
次は,単語二分木共有メモリ構築プログラム。コーパスを読み,単語を切り出して形態素解析を行い見出語 lema に変換し,共有メモリに二分木を構築し,他のプロセスからアクセスするための共有メモリ・ハンドルを出力してウェイトする。ロシア語の見出語解析には Lemmatizer を,単語切り出しには Boost Tokenizer を使っている。
/* -*- coding: utf-8; mode: c++; -*-
* lemwtreesrv.cpp - Lemmatized Word Tree サーバ
* - Corpus ファイルを読む
* - 位置情報と作品テクストを分離する
* - テクストから単語を切り出し,Lemmatizer で見出語に変換し,単語二分木を構築する
* - 二分木ノードに単語,出現回数,位置情報リストを付加する
* 2012(c) isao yasuda.
*/
#include <turglem/lemmatizer.hpp>
#include <turglem/russian/charset_adapters.hpp>
#include <boost/tokenizer.hpp>
#include "lemcorpus.h"
using namespace boost::interprocess;
// グローバル変数
static offset_ptr<tree> words; // 単語ツリーへのオフセットポインタ
static int wordp = 0; // 単語アドレス(作品先頭からの相対位置)
static int flid = 0; // 現作品番号(ファイル名でもある)
// Lemmatizer Russian Grammatical Resources
static char dict[] = "/usr/local/share/turglem/russian/dict_russian.auto";
static char prdm[] = "/usr/local/share/turglem/russian/paradigms_russian.bin";
static char pred[] = "/usr/local/share/turglem/russian/prediction_russian.auto";
static tl::lemmatizer lem; // lemmatizer instance
static tl::lem_result lar; // lemmatizer result
// Lemmatizer 見出語属性構造体
struct wordst {
std::string word; // 見出語
int part; // 品詞
int prio; // プライオリティ
int len; // 長さ
};
// ロシア語形態素解析 Lemmatizer 見出語選定
void lemmatizer(std::string& tword)
{
// Lemmatizer 分析結果オブジェクト件数
size_t rcnt = lem.lemmatize<russian_utf8_adapter>(tword.c_str(), lar);
wordst wst; // 見出語属性
std::vector<wordst> wv; // 見出語属性 vector
std::vector<wordst>::iterator wit; // イテレータ
// rcnt が 0 (解析失敗) なら即終了
if (rcnt < 1) return;
// 見出し語候補 vector を生成し,最大プライオリティを確定
int maxprio = 0;
for (size_t i = 0; i < rcnt; i++) {
u_int32_t src_form = lem.get_src_form(lar, i);
wst.word = lem.get_text<russian_utf8_adapter>(lar, i, 0);
wst.part = lem.get_part_of_speech(lar, i, src_form);
wst.len = wst.word.size();
// 品詞番号でプライオリティ付け
switch (wst.part) {
case 0: wst.prio = 5; break; // существительное 名詞
case 1: wst.prio = 4; break; // прилагательное 形容詞長語尾形
case 2: wst.prio = 3; break; // глагол 動詞
case 3: wst.prio = 5; break; // местоимение 代名詞
case 4: wst.prio = 4; break; // местоимение 代名詞(関係詞など?)
case 5: wst.prio = 4; break; // местоимение 代名詞?
case 6: wst.prio = 4; break; // числительное 数詞
case 7: wst.prio = 4; break; // порядковое числительное 順序数詞
case 8: wst.prio = 3; break; // наречие 副詞
case 9: wst.prio = 3; break; // предикатив 述語/副詞?
case 10: wst.prio = 1; break; // предлог 前置詞
case 11: wst.prio = 1; break; // POSL 後置詞?
case 12: wst.prio = 1; break; // союз 接続詞
case 13: wst.prio = 1; break; // междометие 間投詞
case 14: wst.prio = 1; break; // (INP ?)
case 15: wst.prio = 1; break; // (PHRASE 成句?)
case 16: wst.prio = 1; break; // частица 小詞
case 17: wst.prio = 3; break; // краткое прилагательное 形容詞短語尾形
case 18: wst.prio = 2; break; // причастие 形動詞
case 19: wst.prio = 2; break; // деепричастие 副動詞
case 20: wst.prio = 2; break; // краткое причастие 形動詞短語尾形
case 21: wst.prio = 3; break; // инфинитив 動詞不定形
defaut: wst.prio = 1; break;
}
if (wst.prio >= maxprio)
maxprio = wst.prio;
wv.push_back(wst);
}
// 最大プライオリティ品詞をもつ候補語のなかで最小長のものを確定
int minlen = 1000;
std::vector<std::string> vcand;
for (wit = wv.begin(); wit < wv.end(); wit++) {
if ((*wit).prio == maxprio) {
if ((*wit).len <= minlen) {
minlen = (*wit).len;
vcand.push_back((*wit).word);
}
}
}
// 最小長の候補語の最初のものを見出語に決定
std::vector<std::string>::iterator sit;
for (sit = vcand.begin(); sit != vcand.end(); sit++) {
if ((*sit).size() == minlen) {
tword = *sit;
break;
}
}
}
// コーパス・トークナイザ: corpus 行を単語分割して,vector に格納
// 8 bit の区切り文字 «, » などには未対応 (corpus 作成プログラムで削除しておく)
void corpus_tokenizer(std::string& line, std::vector<std::string>& sv)
{
typedef boost::tokenizer<boost::char_separator<char> > tokenizer;
// 区切り文字定義: -' では分割しない
boost::char_separator<char> sep("\t _:;.,?!~`\"\\[]{}()*&^%$#@+=|<>/",
"", boost::drop_empty_tokens);
tokenizer tok(line, sep);
for(tokenizer::iterator ti = tok.begin(); ti != tok.end(); ti++)
sv.push_back(*ti);
}
// corpus 行をスキャンし,単語をツリーに登録
void corpus_scan(std::string& cl)
{
std::vector<std::string> wordv; // 単語 vector
int posd[4]; // 位置情報
int lwp = 0; // 行内単語アドレス
// corpus line を語分割して単語 vector に格納
corpus_tokenizer(cl, wordv);
// 位置情報,corpus 分離
int i = 0;
for (std::vector<std::string>::iterator it = wordv.begin();
it != wordv.end(); it++) {
if (i < 4)
// 先頭4語(数字)は,位置情報として int 配列に格納
posd[i] = atoi((*it).c_str());
else {
// Lemmatizer を使用して見出語に変換
try {
lemmatizer(*it);
}
catch (const std::exception& e) {
std::cerr << "Lemmatizer error: " << e.what() << "\n";
}
}
i++;
}
// 現作品番号がキーブレークしたら,作品番号を更新し,単語アドレスをリセット(Global)
if (posd[1] != flid) {
flid = posd[1]; // 作品番号
wordp = 0; // 単語アドレス(作品先頭からの相対位置)
}
// 単語 vector の単語,位置情報,単語アドレスを二分木に登録
for (int i = 4; i < wordv.size(); i++)
words->enter_tree
(wordv[i], posd[0], posd[1], posd[2], posd[3], lwp++, wordp++);
}
// 単語情報二分木共有メモリ構築・主処理
int main(int argc, char *argv[])
{
// 引数チェック
if (argc != 2) {
std::cerr << "Usage: " << argv[0] << " corpus-file\n";
exit(8);
}
// 捕捉シグナルとハンドラの登録
signal(SIGTERM, term);
signal(SIGINT, term);
signal(SIGHUP, term);
// 共有メモリを開始前と終了後に削除する
shm_wtree_remove remover;
// 共有メモリに単語二分木を構築
std::cout << "Word Tree Shared Memory Construction.\n";
managed_shared_memory segment(create_only, SHMTREE, SHMTRSZ);
void* pt = segment.allocate(SHMTRSZ - MNGSIZE);
// 使用可能共有メモリの先頭アドレスをポイント
sp = static_cast<char*>(pt);
char* csp = sp;
// 共有メモリに単語二分木を割当
words = new(reinterpret_cast<tree*>(sp)) tree;
sp += sizeof(tree);
// Lemmatizer load dict, paradigms, prediction.
try {
lem.load_lemmatizer(dict, prdm, pred);
}
catch (const std::exception& e) {
std::cerr << "Lemmatizer error: " << e.what() << "\n";
}
// 共有メモリ上に単語二分木を構築
std::ifstream ifs(argv[1]);
std::string ldata;
while (ifs && getline(ifs, ldata)) {
corpus_scan(ldata);
}
// 単語二分木の共有メモリアドレスを連絡するためのハンドルを取得
std::cout << "srv word tree address: " << (void*) csp << "\n";
void* p = static_cast<void*>(csp);
managed_shared_memory::handle_t handle =
segment.get_handle_from_address(p);
std::cout << "srv word tree handle: " << handle << "\n";
// 何か入力されるまでウェイト
while (true) {
std::cout << "Wait. Signal (TERM, INT, HUP) or any key to exit.\n";
char x; std::cin >> x; break;
}
segment.deallocate(pt);
return (0);
}
最後に,他プロセスから共有メモリを参照するクライアントプログラム。単語二分木共有メモリ構築プログラムが与えた共有メモリ・ハンドルをもとに二分木にアクセスし,単語の探索を行う。
/* -*- coding: utf-8; mode: c++; -*-
* lemwtreeclt.cpp - Lemmatized Word Tree クライアント
* - 共有メモリ Word 二分木アドレスを引数のハンドルから取得する
* - 二分木のすべてのノードを出力する
* 2012(c) isao yasuda.
*/
#include "lemcorpus.h"
using namespace boost::interprocess;
int main (int argc, char* argv[])
{
// 引数チェック
if (argc != 2) {
std::cerr << "Usage: " << argv[0] << " handle\n";
exit(8);
}
// 共有メモリ・オブジェクトを取得
managed_shared_memory segment(open_only, SHMTREE);
// ハンドルから共有メモリ・リソースのアドレスを取得
managed_shared_memory::handle_t handle = 0;
handle = static_cast<managed_shared_memory::handle_t>(std::atoi(argv[1]));
void* vp = segment.get_address_from_handle(handle);
std::cerr << "clt word tree address: " << vp << "\n";
// void ポインタを tree ポインタにキャスト
offset_ptr<tree> sv = reinterpret_cast<tree*>(vp);
// tree の全ノードを出力
sv->print_tree();
// node 探索
std::string fw = "НЕ";
std::cout << "find " << fw << "\n";
sv->find_tree(fw);
return 0;
}
試験
上記プログラムを以下の『エヴゲーニイ・オネーギン』からのコーパスデータ・サンプルで実行してみる。行の先頭にあるのは,別途コーパス作成プログラムで付加した管理情報(ジャンル番号,作品番号 = HTML ファイル名,HTML 行 ID,行番号)である。
03:0837:0101001:000021 Мой дядя самых честных правил,
03:0837:0101002:000022 Когда не в шутку занемог,
03:0837:0101003:000023 Он уважать себя заставил
03:0837:0101004:000024 И лучше выдумать не мог.
03:0837:0101005:000025 Его пример другим наука;
03:0837:0101006:000026 Но, боже мой, какая скука
03:0837:0101007:000027 С больным сидеть и день и ночь,
03:0837:0101008:000028 Не отходя ни шагу прочь!
03:0837:0101009:000029 Какое низкое коварство
03:0837:0101010:000030 Полуживого забавлять,
03:0837:0101011:000031 Ему подушки поправлять,
03:0837:0101012:000032 Печально подносить лекарство,
03:0837:0101013:000033 Вздыхать и думать про себя
03:0837:0101014:000034 Когда же черт возьмет тебя!
二分木構築サーバを起動する。srv word tree handle: 192 行が共有メモリ・ハンドルの表示である。
% lemwtreesrv corpus-eo.txt
Word Tree Shared Memory Construction.
srv word tree address: 0x1010000c0
srv word tree handle: 192
Wait. Signal (TERM, INT, HUP) or any key to exit.
q
Word Tree Shared Memory Deconstruction.
%
Mac OS X でのアクセスクライアントの実行結果を以下に示す。二分木構築サーバが出力した共有メモリ・ハンドルを引数に取って,二分木にアクセスする。実行結果より,他のプロセスからもきちんと共有メモリデータが見えることがわかる。
% lemwtreeclt 192
clt word tree address: 0x1002000c0
БОГ 1 3:837:101006:26:1:24;
БОЛЬНОЙ 1 3:837:101007:27:1:29;
В 1 3:837:101002:22:2:7;
ВЗДЫХАТЬ 1 3:837:101013:33:0:51;
ВЗЯТЬ 1 3:837:101014:34:3:59;
ВЫДУМАТЬ 1 3:837:101004:24:2:16;
ДЕНЬ 1 3:837:101007:27:4:32;
ДРУГОЙ 1 3:837:101005:25:2:21;
ДУМАТЬ 1 3:837:101013:33:2:53;
ДЯДЯ 1 3:837:101001:21:1:1;
ЖЕ 1 3:837:101014:34:1:57;
ЗАБАВЛЯТЬ 1 3:837:101010:30:1:44;
ЗАНЕМОЧЬ 1 3:837:101002:22:4:9;
ЗАСТАВИТЬ 1 3:837:101003:23:3:13;
И 4 3:837:101004:24:0:14; 3:837:101007:27:3:31; 3:837:101007:27:5:33;
3:837:101013:33:1:52;
КАКОЙ 2 3:837:101006:26:3:26; 3:837:101009:29:0:40;
КОВАРСТВО 1 3:837:101009:29:2:42;
КОГДА 2 3:837:101002:22:0:5; 3:837:101014:34:0:56;
ЛЕКАРСТВО 1 3:837:101012:32:2:50;
МОЙ 2 3:837:101001:21:0:0; 3:837:101006:26:2:25;
МОЧЬ 1 3:837:101004:24:4:18;
НАУКА 1 3:837:101005:25:3:22;
НЕ 3 3:837:101002:22:1:6; 3:837:101004:24:3:17; 3:837:101008:28:0:35;
НИ 1 3:837:101008:28:2:37;
НИЗКИЙ 1 3:837:101009:29:1:41;
НО 1 3:837:101006:26:0:23;
НОЧЬ 1 3:837:101007:27:6:34;
ОН 3 3:837:101003:23:0:10; 3:837:101005:25:0:19; 3:837:101011:31:0:45;
ОТХОДИТЬ 1 3:837:101008:28:1:36;
ПЕЧАЛЬНЫЙ 1 3:837:101012:32:0:48;
ПОДНОСИТЬ 1 3:837:101012:32:1:49;
ПОДУШКА 1 3:837:101011:31:1:46;
ПОЛУЖИВОЙ 1 3:837:101010:30:0:43;
ПОПРАВЛЯТЬ 1 3:837:101011:31:2:47;
ПРАВИЛО 1 3:837:101001:21:4:4;
ПРИМЕР 1 3:837:101005:25:1:20;
ПРО 1 3:837:101013:33:3:54;
ПРОЧЬ 1 3:837:101008:28:4:39;
С 1 3:837:101007:27:0:28;
САМЫЙ 1 3:837:101001:21:2:2;
СЕБЯ 2 3:837:101003:23:2:12; 3:837:101013:33:4:55;
СИДЕТЬ 1 3:837:101007:27:2:30;
СКУКА 1 3:837:101006:26:4:27;
ТЫ 1 3:837:101014:34:4:60;
УВАЖАТЬ 1 3:837:101003:23:1:11;
ХОРОШИЙ 1 3:837:101004:24:1:15;
ЧЕРТ 1 3:837:101014:34:2:58;
ЧЕСТНЫЙ 1 3:837:101001:21:3:3;
ШАГ 1 3:837:101008:28:3:38;
ШУТКА 1 3:837:101002:22:3:8;
find НЕ
НЕ 3 3:837:101002:22:1:6; 3:837:101004:24:3:17; 3:837:101008:28:0:35;
%
サーバ側では二分木共有メモリアドレスは 0x1010000c0 であるのに対し,クライアント側では 0x1002000c0 になっている。これは OS の仮想記憶管理に依存するが,このようにそれぞれのプロセスにおいて単一の共有メモリ領域がプロセス毎に違う仮想記憶アドレスにマッピングされる場合がある。だからこそ,共有メモリ内のポインタに仮想記憶アドレスそのものを記憶させるとまずいのである。ちなみに,FreeBSD で実行した結果では,二分木アドレスは,サーバ,クライアント両側ともに 0x48400060 であり,同じだった。
出力の意味は,「見出語 出現回数 ジャンル番号:作品番号:行ID:行番号:行先頭からの相対位置:作品先頭からの相対位置(複数あり)」である。例えば,КАКОЙ 2 3:837:101006:26:3:26; 3:837:101009:29:0:40; というのは,単語 КАКОЙ が処理コーパスにおいて,26:3:26 = 26 行目・行語位置 3(行先頭から 4 語目)・作品語位置 26(作品先頭から 27 語目),29:0:40(同左)の 2 回出現していることを示す。「作品番号」と「行ID」は,作品コーパスに対応する HTML のファイル名とその行の ID 要素とに対応しており,この出力結果からコーパス・コンテキストを HTML の当該場所へのリンクによって確認できる設計になっている(次のプロトタイプ作成課題はこれ)。
参考文献
やっぱりストラウストラップによる C++ 言語解説につきる。配置 new のキモについてもきちんと書かれている。

長尾高弘訳
アジソン・ウェスレイ・パブリッシャーズ・ジャパン