単語条件式の入力
図 3. 中の "Выражение" に,コンコーダンス解析したい単語の条件式を記述します.単語条件式は通常文字で入力指定するのが基本です.通常文字とは単語の綴りを構成するロシア文字,ラテンアルファベット文字です.いわゆる半角文字で入力する必要があります. "стих" と指定すると,これに完全一致する単語について KWIC を生成します.
単語条件式は通常文字のほかに,不定文字,論理演算子,括弧を記述することができます.
不定文字は 0 個以上の任意の文字にマッチする "*" 及び,1 個の任意の文字にマッチする "." が指定できます.例えば, "крас*" という指定は "крас", "красный", "красавица", "краса", ... と "крас" に任意の文字列 (文字 0 個も含む) が続く単語に適合します. "крас*а" ならば "крас" ではじまり "а" で終了する単語指定になります.これに対し, "крас." は "краса", "красе", "красы", ... と "крас" に 1 文字だけ任意の文字が付く単語を抽出する指定になります. "*" だけを指定すると,コーパスの全単語の KWIC 作成を指示したことになります. ”....” と指定すると 4 文字からなる単語をすべて抽出します.こうして,通常文字と不定文字により単語条件の単項式を指定できるわけです.単項式を空白文字で区切って複数指定することができます.
論理演算子と括弧をスペースで区切って入力することにより,複数の単項式を組合わせ,より複雑な多項式条件設定を行うことができます.論理演算子は論理積 (AND) "*", 論理和 (OR) "+", 論理差 (NOT) "#" を指定できます.演算の優先順位は算術演算と同じく左から評価され "*" > "+" = "#" となっています. "*" 記号は任意文字マッチ不定文字と論理演算子と意味が二つありますが,文字に直接付く (任意文字マッチ不定文字) か,空白/括弧を置く (論理演算子) かによって判断されます.例えば, "крас* * *ого" という指定は,中央の空白で区切られた "*" のみ論理演算子と解釈され,語頭 "крас" かつ語末 "ого" の単語抽出条件指定になります.すなわち, "красного", "красивого", "красноречивого", ... がマッチします. "крас* # *ого" は,語末 "ого" 以外の単語にマッチします.
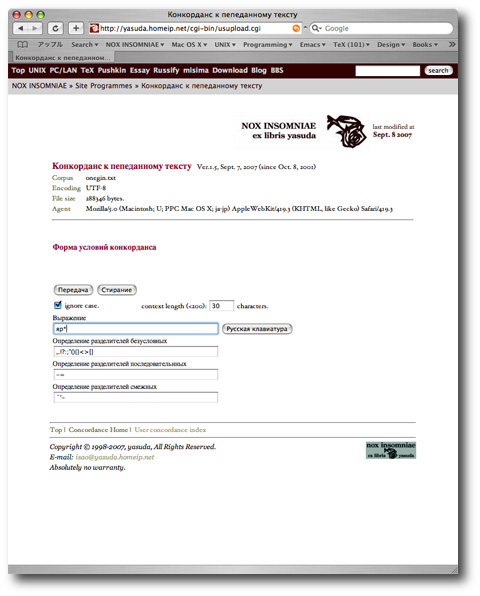
括弧: "(" 開括弧,あるいは ")" 閉括弧は二項論理演算の優先順位を算術的に変更したいときに指定します.必ず開括弧と閉括弧を対で記述する必要があります.括弧の対のなかにさらに括弧の対を指定する,いわゆる入れ子も可能です.「単項式A + 単項式B * 単項式C」は論理演算子の優先順位に従って,まず B * C がチェックされ,その結果と A の結果の論理和を取ります.「(単項式A + 単項式B) * 単項式C」と括弧を付加すると,A + B が先に演算評価されるように変更できます. "крас* # (*ыми + *ым)" という条件式は, "крас" ではじまる単語で,かつ語末が "ыми" でも "ым" でもないもの ("красный", "красного" など) にマッチします.図 3. の例では "яр*" として,「"яр" ではじまりそのあとに任意の文字が続く単語」という条件指定を行っています.
注意すべきは,図 3. "Выражение" 単語条件式で入力するのは「単語の構成文字条件」ということです.インターネットの検索サイトのクエリのように「文書」を探すのではなく,対象コーパスにおいて指定条件に合致する「単語」の出現コンテクストを求めたいわけです. "стих творение" のように指定すると,空白で区切って二つの単語条件単項式が指定されたことになり, "стих" と "творение" に完全一致する単語のコンテクストを抽出することになります.多項式 "стих + творение" と等価です. "стих" と "творение" を含む文書もしくはテキスト断片を探すことにはなりません.目的が違います.仮に "стих * творение" と指定しても,そんな単語が存在するはずがありません ("стих" に完全一致しかつ "творение" にも完全一致するということはありえません). "стих* * *творение" ならば "стих" ではじまり "творение" で終了する単語 "стихотворение" がヒットして KWIC が生成されるかも知れません.この場合, "стихотворения" は指定条件に合致しないので,抽出されません.ロシア語格変化を考慮してマッチさせたいのであれば, "стих* * *творени*" (多項式条件) あるいは "стих*творени*" (単項式条件) と指定すべきでしょう.ただし,この二つの等価条件は,後者の単項式条件のほうが処理方式上,高速に動作します.
コーパスが UTF-8 または X11 Ctext の場合は,条件式にロシア文字のみならず,西欧語,東欧語で用いられるアクセント付き文字を指定できます.
条件式設定の詳細説明は「スラヴ学研究者のためのコンピュータ・リテラシーのために: 単語統計: 検索(パターン適合試験)機能」を参照してください.
ロシア文字の入力は,最近の Windows (2000,XP), Mac OS X では多言語入力メソッドでサポートされています.オペレーティング・システムの設定が面倒な場合,本システムではロシア語入力支援機能を組み込んでありますので,こちらをご利用いただけます.図 3. の "Русская клавиатура" をクリックすると図 4. に示す小さな疑似キーボード・ウィンドウが右上にオープンします.キーボード配列は初期値では "яшерты" と呼ばれる Phonetic 配列ですが,ロシアで一般的な "йцукен" 配列も選択可能です.文字をクリックすると図 3. の"Выражение" テキストボックスに当該文字が入力されます.
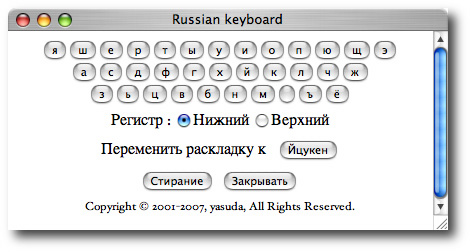 図 4. 疑似ロシア語キーボード
図 4. 疑似ロシア語キーボード
図 3. "ignore case" チェックボックスにチェックを入れると,単語のマッチング解析のときに大文字・小文字の違いを無視します.条件式に指定した大文字・小文字の違いを忠実に区別させたい場合にはチェックを外してください.
図 3. "content length" のボックスに,コンコーダンス解析で条件にマッチした単語の前後に現れるテキスト文字長を指定できます.200 以下の自然数を指定します.あらかじめ 30 が設定されています.
図 3. "Определение разделителей ..." は単語の区切り文字の定義です. "слово, слово." というテキストにおけるカンマやピリオドのような文字のことです.必ず単語を区切る文字 (Определение разделителей безусловных), 連続して現れると区切り文字と判断する文字 (Определение разделителей последовательных), 及び,区切り文字と隣接して現れたときのみ区切り文字とみなされる文字 (Определение разделителей смежных) を指定します.フォームには初期状態の定義がなされています.これをわざわざ修正せず,そのままで使ってもよいと思います.区切り文字に関する詳細は「スラヴ学研究者のためのコンピュータ・リテラシーのために: 単語統計: staslova における「単語」」を参照してください.
コンコーダンス解析結果
図 3. 画面で条件を入力したら, "Передача" ボタンを押下するとコンコーダンス処理が開始されます.処理時間は主にコーパスの容量に依存します.完了すると図 5. のような画面で,マッチした単語の出現回数とそのコンテキストが KWIC 形式で報告されます. KWIC 表の部分を図 6. に示します.条件にマッチした単語はハイライト表示されます.単語の前後のテキストは,図 3. "content length" 指定の長さで機械的に切り落としますので,単語の途中で切れている場合があります.右端の "Line:Pos" 欄はコーパスの先頭行を 1 とした場合の行番号 (Line) と,先頭の語を 1 とした場合の単語番号 (Pos) を示しています.
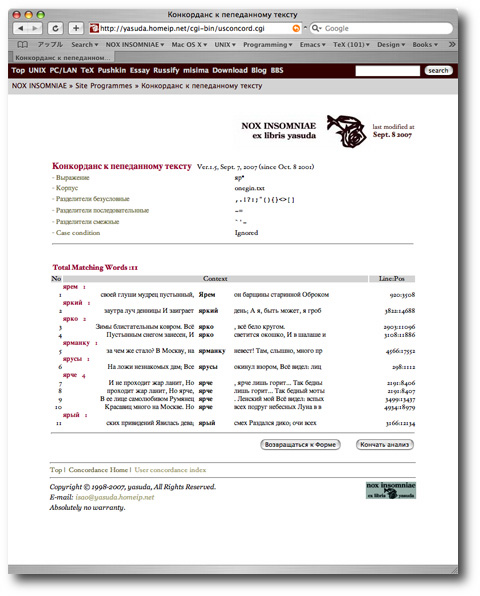 図 5. コンコーダンス結果画面
図 5. コンコーダンス結果画面
 図 6. コンコーダンス KWIC 表
図 6. コンコーダンス KWIC 表
図 6. の例では, "яр*" という条件に対し, ярем 1, яркий 1, ярко 2, ярманку 1, ярусы 1, ярче 2, ярый 1, 合計 11 用例がマッチしたことを示しています.同一行でヒットしている ярче の 2 例は,それぞれヒットした位置でコンテキストが表示されています.この KWIC 表をコピーして,文書作成に利用します.