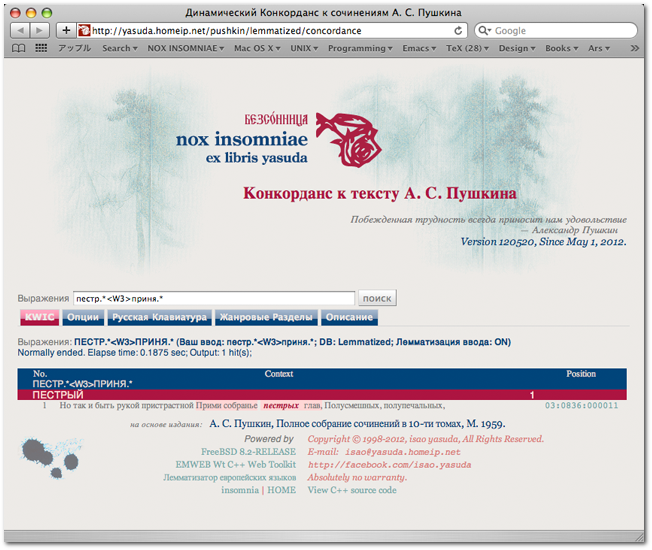
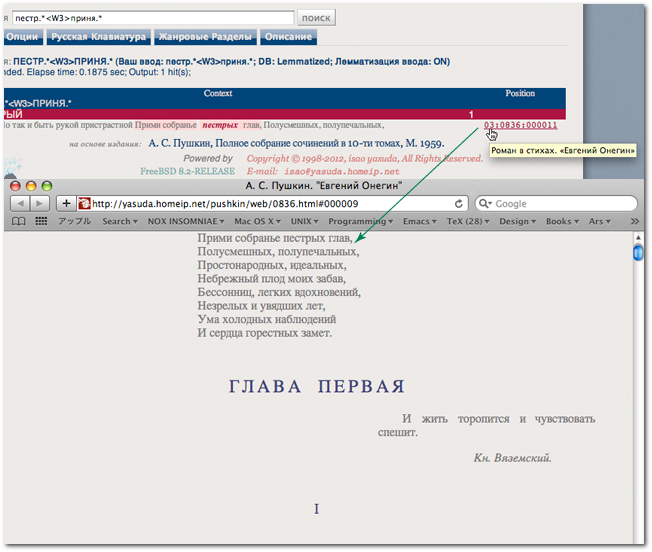
|
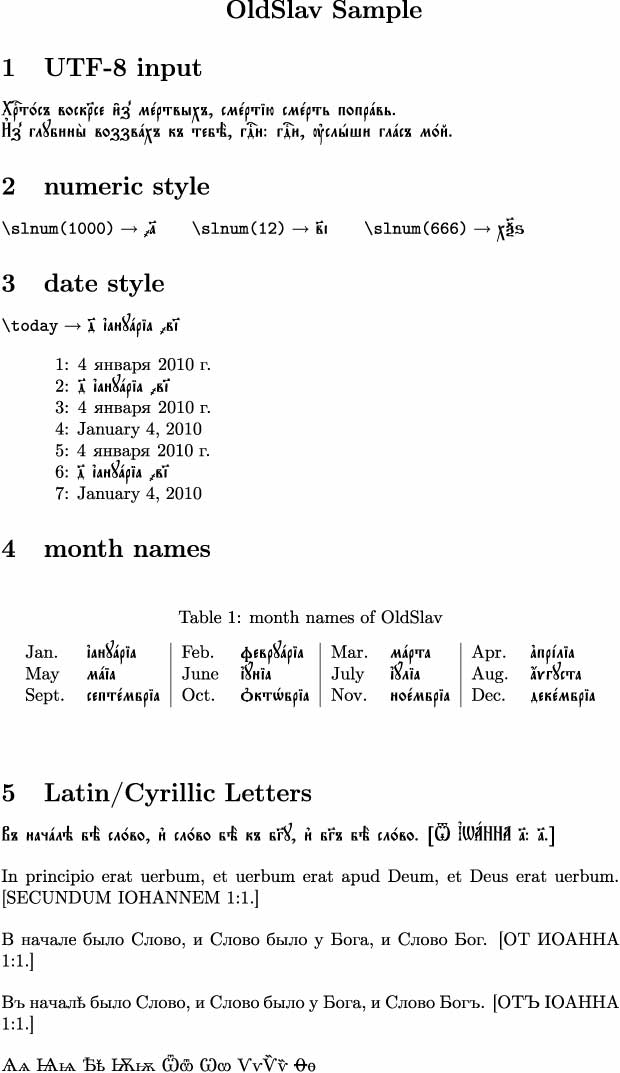
«Uso2022» представляет собой программа,
которая конвертирует текст, написанный на языке русском,
французском, германском и т. д., на «Compound Text»,
или транскрибирует кириллицы на знаки в LaTeX'е.
«Compound Text» — один из форматов, построенных
на принципах ISO 2022 для написания мульти-лингвистического текста.
Он определен в UNIX X Window System (после X11R5).
«Uso2022» имеет функции:
-
Построить Compound Text, вводя «escape sequences»
в тексты, кодированные на ISO 8859-5 (Cyrillic),
ISO 8859-1 (Latin-1), ISO 8859-2 (Latin-2) или ISO 8859-7 (Greek).
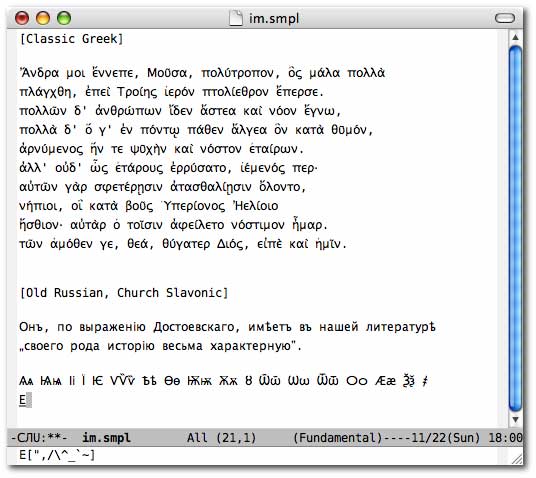
Таким образом Вы можете редактировать русский текст
на Mule вместе с японском, и т. д.
Mule («MULtilingual Enhancement to GNU Emacs»)
— один из вариантов GNU Emacs, но это I18N-Emacs,
расширенный японскими исследователями ETL
(Electrotechnical Laboratory),
может управлять много языков вместе в одном и том же тексте.
Включают Mule во FreeBSD japanese ports.
-
Транскрибировать Compound Text из русских символов,
латинских специальных символов и акцентов на символы,
определенные в системе LaTeX команды.
При этом Вы можете приписывать японских символы
на кодировке ISO 2022-JP (JIS X 0208):
«кандзи» —
иероглиф, японский фигурный символ,
и «кану» — японскую слоговую азбуку.
Транскрипция придерживается следующих правил:
-
русские символы — основаны на кодировке
Вашингтонском Университетом, использованной в стиле «Babel»
многоязычного пакета LaTeX'а
-
латинские специальные символы и акценты —
основаны на кодировке «T1» в системе LaTeX2e
Итак Вы можете писать документы LaTeX'а
на русских буквах, разумеется,
вместе с буквами японского, французского, германского языка.
После этого, перед верстки LaTeX документа, транскрибируйте
с помощью «Uso2022».
-
Транскрибировать русские символы,
латинские специальные буквы и акценты в тексте, кодированном
на ISO 8859-5 (Cyrillic), ISO 8859-1 (Latin-1),
или ISO 8859-2 (Latin-2), на символы, определенные
в системе LaTeX команды.
Таким образом Вы можете просто вносить
русские тексты из Интернета Internet в документы LaTeX'а.
Об описании конкретной спецификации и
установки программ см.:
компьютерная грамотность UNIX для славяноведов
(документы программы на японском языке)
Эта программа представляет собой free software.
Свободно используйте и перестраивайте, если не коммерчески.
Но "absolutely no warranty":
Употребляйте в своем ответе во всем.
Программа выработана на основе FreeBSD 2.2.5,
GNU C compiler.
|