


Next: 書式
Up: 単語統計
Previous: 検索(パターン適合試験)機能
定義でわかるとおり、staslova での「単語」はあくまで定義した区切りで
切り出されたものです。
仮に日本語のテキストに対し、区切り文字定義を行わないで処理を行うと、
どういうことが起こるかというと、日本語の場合空白文字はあまり利用されない
ため、改行文字の単位で大きな「単語」が多数出力されるのではないかと思います。
たとえば、「どういうことが起こるかというと、日本語の場合空白文字はあまり
利用されないため、」という「単語」が。
逆にこうした原理を利用して、データ作成と定義の仕方を工夫すると
「単語」のイメージを越えた解析に利用できます。
たとえば次のようにすれば、「文」の特性の適合試験ができます。
- 1.
- 対象テキストを1行/1文に修正する。
- 2.
- スペース文字(固定区切り)はたとえば``_''などの
明らかに約束で置き換えたことがわかる文字
-- 原文で使われていない文字 --
に置換する。
(Mule の文字リプレース機能を使う)
``I love you.''
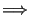 ``I_love_you.''
``I_love_you.''
- 3.
- 区切り文字定義を固定区切りのみとする(要するに定義を行わない)。
これで改行文字のみが区切りと認識され、
1 行 1 文が「1 語」として扱われることになります。
- 4.
- 検索式のたて方で、たとえば次のような分析ができるようになります。
- 単語 A と単語 B が同時に使われている文はないか。
se *A* * *B*
- あるフレーズが否定詞とともに用いられているパターンはどうか。
se *this*is*phrase* * (*not* + *no* + *'t*)
- 先頭が XX で開始する詩行は何行あるか。
se 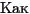 _*
_*
- etc, etc, ...
staslova は 1 行、1 単語の最大長は 4,096 バイト(漢字で約 2,000 字)
まで可能な設定なので、
石川淳や谷崎潤一郎のような息の長い文の場合でも「1 語」として
収容できるのではないかと思います。
| ホームに戻る | もくじに戻る |
