概要 |
Namazu はフリーの日本語全文検索エンジンソフトである.全文検索ソフトウェアは高速化のため言語の特徴に依存したチューニングが施されているものであり,Namazu も 日本語 EUC を前提とした作りとなっている.本稿では Namazu2 によりロシア語を含む UTF-8 エンコードの Web ページの検索を行う方法を示す.
|
|
インストール |
Namazu2 (2004.3 現在 2.0.12) を ports からインストールする.前提となる Nkf などのソフトは自動的に組み込まれる.Namazu はインデックス作成の際,日本語形態素解析を行うため,茶筅もしくは Kakashi を必要とするので,make するときにどちらを利用するかをオプションで指定する(ここでは茶筅を用いることとする).また別途 WvWare,Xlhtml,Lv,Xpdf といったフィルタ・ソフトウェアを導入することにより,Microsoft Word や Microsoft Excel,PDF ドキュメントの検索インデックスを作成できる. # cd /usr/ports/japanese/namazu2 # make -D WITH_CHASEN install # cd ../xpdf # make install # cd ../../textproc/wv # make install # cd ../xlhtml # make install # cd ../../misc/lv # make install
|
|
Namazu 設定 |
Namazu の検索インデックスを作成するツールである Mknmz の動作を定義するリソースファイルを準備する.ここでポイントとなるのは Web ページを生成するためのテンプレートを格納するディレクトリ指定,フィルタの指定であると思う.検索結果のページはテンプレートのカスタマイズによって好みのデザインが可能である.詳細はマニュアル,インターネット・リソースを参照いただきたい.私のサイトの全文検索ページのために作成したリソースファイル及びテンプレートを,以下に参考までに設置しておく.
Web で検索するための CGI モジュールを cgi-bin にコピーする.Apache などの Web サーバの設定についてはインターネット・リソースを参照いただきたい. # cp -p /usr/local/libexec/namazu.cgi /usr/local/www/cgi-bin CGI にアクセスするための Web ページを準備する.例として私のサイトの全文検索ページの HTML ソースを参照していただきたい. CGI モジュールの動作を設定する以下のような .namazurc ファイルを作成し,cgi-bin にコピーする.設定パス,URL は適宜修正が必要である. ## Index: インデックス格納パス Index /var/webidx/ ## Template: テンプレート格納パス Template /usr/local/etc/namazu/tmpl ## Replace: インデックス作成入力パスを Web URL に置き換える指定 Replace /home/(.*)/public_html/ http://webserver/~\1/ Replace /tmp/webidx/(.*)/ http://webserver/~\1/ ## Logging: ロギング取得設定 Logging off ## Lang: 言語設定 Lang ja
|
|
検索インデックスの作成 |
Namazu でロシア語を検索するためには検索インデックス入力ファイルにおいて UTF-8 コードを EUC (全角文字) に変換しておくとよい.つまり,検索対象となる HTML のうち UTF-8 でエンコードされているものを抽出 (find) し,これにコード変換を施した (iconv) ワークファイルに対しインデックスを作成するわけである.検索結果からリンクする公開 HTML は UTF-8 エンコードのままであることに注意されたい.毎回 UTF-8 の HTML を作成するのも無駄であるので,前回実行のタイムスタンプよりも新しいもののみを抽出するようにして,以降に更新された HTML のみを対象とするのがよい.この一連の処理を行うスクリプトの例を示す.
#!/bin/sh
#
# Namazu Web index generation
# (c) 2004, isao yasuda
LANG=ja_JP.EUC
export LANG
src=/home/user/public_html # 公開 HTML Top Dir
OBJ="./*.html ./subdir1 ./subdir2" # 検索対象
TMP=/tmp/webidx/html # ワーク Dir
STAMP=/var/webidx/stamp # タイムスタンプ
MKNMZRC=/usr/local/etc/namazu/mknmzrc # mknmz リソース
IDXDIR=/var/webidx # 検索インデックス Dir
#
# 検索対象 HTML 抽出
#
cd $SRC
# Top 下からタイムスタンプより新しい HTML を抽出しワークに出力
echo '*** include HTMLs newer than time-stamp ...'
find -L $OBJ \
\( -newer $STAMP -name "*html" \) | \
xargs tar cf - | \
( cd $TMP; tar xvf - )
# 同様に UTF-8 の HTML ファイル名を特定し /tmp/UTF8 に出力
echo '*** code convert from UTF-8 to EUC ...'
find -L $OBJ
\( -newer $STAMP -name "*html" \) | \
xargs grep -H -e "charset=[Uu][Tt][Ff]-8" | \
cut -d : -f 1 | uniq > /tmp/UTF8
# UTF-8 の HTML ファイルをコード変換 (iconv) しワークに出力
for i in `cat /tmp/UTF8`
do
iconv -c -f UTF-8 -t EUC-JP $i | \
sed 's/charset=[Uu][Tt][Ff]-8/charset=EUC-JP/g' > $TMP/$i
done
# /tmp/UTF8 の削除,タイムスタンプの更新
rm -f /tmp/UTF8
touch $STAMP
#
# Namazu インデックスの生成
#
echo '*** index generation ...'
/usr/local/bin/mknmz -a -O $IDXDIR -f $MKNMZRC -k $TMP
echo 'done.'
|
|
ロシア語クエリーの入力 |
Web ブラウザ (Mozilla) の入力フォームには,いわゆる全角でロシア語を入力する.Kinput2 などを利用して通常日本語を入力するかと思うが,キリル文字はかな漢字変換で入力するとなると記号選択となって結構面倒である.そこでローマ字変換方法をカスタマイズし,"xrA" などとタイプしてキリル文字の "А" が入力できるような工夫があるとよい. 私は日本語入力ソフトとして(株)オムロンソフトウェアの Wnn7 のインプットメソッド Xwnmo を Egg 風入力方式で利用している.フリーのかな漢字変換辞書では変換効率に限界があり,いらいらさせられることが多く,かな漢字変換くらいは商用ソフトウェアを導入したいものである.この場合,~/.Wnn7/rk/2B_ROMKANA.egg にキリル文字の変換方法を記述しておけば上記のようにローマ字キリル文字変換が可能となる.参考までに私の 2B_ROMKANA.egg を設置しておく.これに従えば,"Пушкин" と入力するには "xrPxruxr[xrkxrixrn" とタイプして確定する. フリーの日本語インプットメソッドとしてユーザの多い Kinput2 でも ccdef ファイルで同様なカスタマイズが可能なはずだ.詳細は
|
|
Namazu の実行例 |
例として,上記の方法でインデックスを作成している私のサイトの検索ページの入力と出力を示す. 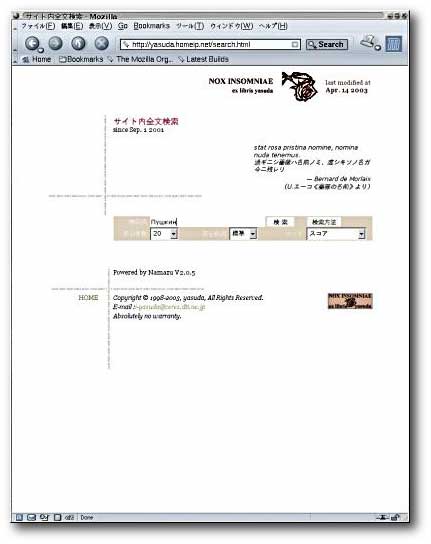
Mozilla フォームへのキリル文字入力

Namazu 検索結果
|